ML Libraries
AutoML
Python
Optuna

Optuna is an automatic hyperparameter optimization software framework, particularly designed for machine learning. It features an imperative, define-by-run style user API. Thanks to our define-by-run API, the code written with Optuna enjoys high modularity, and the user of Optuna can dynamically construct the search spaces for the hyperparameters.
Optuna has modern functionalities as follows:
Lightweight, versatile, and platform agnostic architecture
Handle a wide variety of tasks with a simple installation that has few requirements.
Pythonic search spaces
*Define search spaces using familiar Python syntax including conditionals and loops.*
Efficient optimization algorithms
Adopt state-of-the-art algorithms for sampling hyperparameters and efficiently pruning unpromising trials.
Easy parallelization
Scale studies to tens or hundreds of workers with little or no changes to the code.
Quick visualization
Inspect optimization histories from a variety of plotting functions.
Optuna is popular and is generally regarded as accessible to beginners.
Hyperopt

Hyperopt is a Python library for serial and parallel optimization over awkward search spaces, which may include real-valued, discrete, and conditional dimensions.
Currently three algorithms are implemented in hyperopt:
- Random Search
- Tree of Parzen Estimators (TPE)
- Adaptive TPE
Hyperopt has been designed to accommodate Bayesian optimization algorithms based on Gaussian processes and regression trees, but these are not currently implemented.
All algorithms can be parallelized in two ways, using:
- Apache Spark
- MongoDB
HyperOpt is also extremely popular.
NNI

NNI automates feature engineering, neural architecture search, hyperparameter tuning, and model compression for deep learning. Find the latest features, API, examples and tutorials in our official documentation.
The documentation has several tutorials and quick-start guides for a variety of situations, but its coverage for nonstandard operations is less than thorough (and in some places is outdated and/or self-contradictory).
Auto-PyTorch
While early AutoML frameworks focused on optimizing traditional ML pipelines and their hyperparameters, another trend in AutoML is to focus on neural architecture search. To bring the best of these two worlds together, we developed Auto-PyTorch, which jointly and robustly optimizes the network architecture and the training hyperparameters to enable fully automated deep learning (AutoDL).
Auto-PyTorch is mainly developed to support tabular data (classification, regression) and time series data (forecasting). The newest features in Auto-PyTorch for tabular data are described in the paper “Auto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL” (see below for bibtex ref). Details about Auto-PyTorch for multi-horizontal time series forecasting tasks can be found in the paper “Efficient Automated Deep Learning for Time Series Forecasting”.
FLAML

FLAML is a lightweight Python library for efficient automation of machine learning and AI operations. It automates workflow based on large language models, machine learning models, etc. and optimizes their performance.
FLAML enables building next-gen GPT-X applications based on multi-agent conversations with minimal effort. It simplifies the orchestration, automation and optimization of a complex GPT-X workflow. It maximizes the performance of GPT-X models and augments their weakness.
For common machine learning tasks like classification and regression, it quickly finds quality models for user-provided data with low computational resources. It is easy to customize or extend. Users can find their desired customizability from a smooth range.
It supports fast and economical automatic tuning (e.g., inference hyperparameters for foundation models, configurations in MLOps/LMOps workflows, pipelines, mathematical/statistical models, algorithms, computing experiments, software configurations), capable of handling large search space with heterogeneous evaluation cost and complex constraints/guidance/early stopping.
Featuretools

Featuretools automatically creates features from temporal and relational datasets.

DeepHyper

DeepHyper is a powerful Python package for automating machine learning tasks, particularly focused on optimizing hyperparameters, searching for optimal neural architectures, and quantifying uncertainty through the deep ensembles. With DeepHyper, users can easily perform these tasks on a single machine or distributed across multiple machines, making it ideal for use in a variety of environments. Whether you’re a beginner looking to optimize your machine learning models or an experienced data scientist looking to streamline your workflow, DeepHyper has something to offer. So why wait? Start using DeepHyper today and take your machine learning skills to the next level!
AutoGluon

See the website for several Quick Start guides and tutorials.
AdaNet

AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention. AdaNet builds on recent AutoML efforts to be fast and flexible while providing learning guarantees. Importantly, AdaNet provides a general framework for not only learning a neural network architecture, but also for learning to ensemble to obtain even better models.
Neuraxio

The world’s cleanest AutoML library ✨ - Do hyperparameter tuning with the right pipeline abstractions to write clean deep learning production pipelines. Let your pipeline steps have hyperparameter spaces. Design steps in your pipeline like components. Compatible with Scikit-Learn, TensorFlow, and most other libraries, frameworks and MLOps environments.
Time series
Python
Temporian

Temporian is a library for safe, simple and efficient preprocessing and feature engineering of temporal data in Python. Temporian supports multivariate time-series, multivariate time-sequences, event logs, and cross-source event streams.
functime

functime is a machine learning library for time-series predictions that just works.
- Fully-featured: Powerful and easy-to-use API for forecasting and feature engineering (tsfresh, Catch22).
- Fast: Forecast 100,000 time series in seconds on your laptop
- Efficient: Extract 100s of time-series features in parallel using Polars
- Battle-tested: Algorithms that deliver real business impact and win competitions
tsflex
tsflex … [is] a sequence first Python toolkit for processing & feature extraction, making few assumptions about input data. This makes tsflex suitable for use-cases such as inference on streaming data, performing operations on irregularly sampled series, a holistic approach for operating on multivariate asynchronous data, and dealing with time-gaps.
GluonTS
PyTorch-Forecasting
Explainable DL
Python
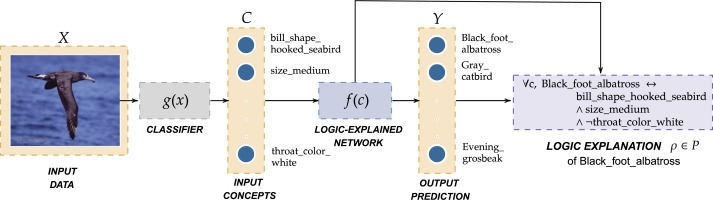
Logic Explained Networks
The Logic Explained Network is a python repository providing a set of utilities and modules to build deep learning models that are explainable by design. This library provides both already implemented LENs classes and APIs classes to get First-Order Logic (FOL) explanations from neural networks.

Streaming ML
River
See also deep-river at https://github.com/online-ml/deep-river: “deep-river is a Python library for online deep learning. deep-river’s ambition is to enable online machine learning for neural networks. It combines the river API with the capabilities of designing neural networks based on PyTorch.”
Plotting and Data Visualization
Python
seaborn
Perspective
Perspective is an interactive analytics and data visualization component, which is especially well-suited for large and/or streaming datasets. Use it to create user-configurable reports, dashboards, notebooks and applications, then deploy stand-alone in the browser, or in concert with Python and/or Jupyterlab.
scikit-learn alternatives
PyCaret
Architecture-Specific
Transformers
Python
HuggingFace transformers
See also this list of “Awesome projects built with transformers.”
NLP
Python
spaCy
spaCy is a library for advanced Natural Language Processing in Python and Cython. It’s built on the very latest research, and was designed from day one to be used in real products.
spaCy comes with pretrained pipelines and currently supports tokenization and training for 70+ languages. It features state-of-the-art speed and neural network models for tagging, parsing, named entity recognition, text classification and more, multi-task learning with pretrained transformers like BERT, as well as a production-ready training system and easy model packaging, deployment and workflow management. spaCy is commercial open-source software, released under the MIT license.
Appears to use PyTorch for GPU support.
FARM (Framework for Adapting Representation Models)

Contextualized Topic Models

Contextualized Topic Models (CTM) are a family of topic models that use pre-trained representations of language (e.g., BERT) to support topic modeling. See the papers for details:
- Bianchi, F., Terragni, S., & Hovy, D. (2021). Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence. ACL. https://aclanthology.org/2021.acl-short.96/
- Bianchi, F., Terragni, S., Hovy, D., Nozza, D., & Fersini, E. (2021). Cross-lingual Contextualized Topic Models with Zero-shot Learning. EACL. https://www.aclweb.org/anthology/2021.eacl-main.143/
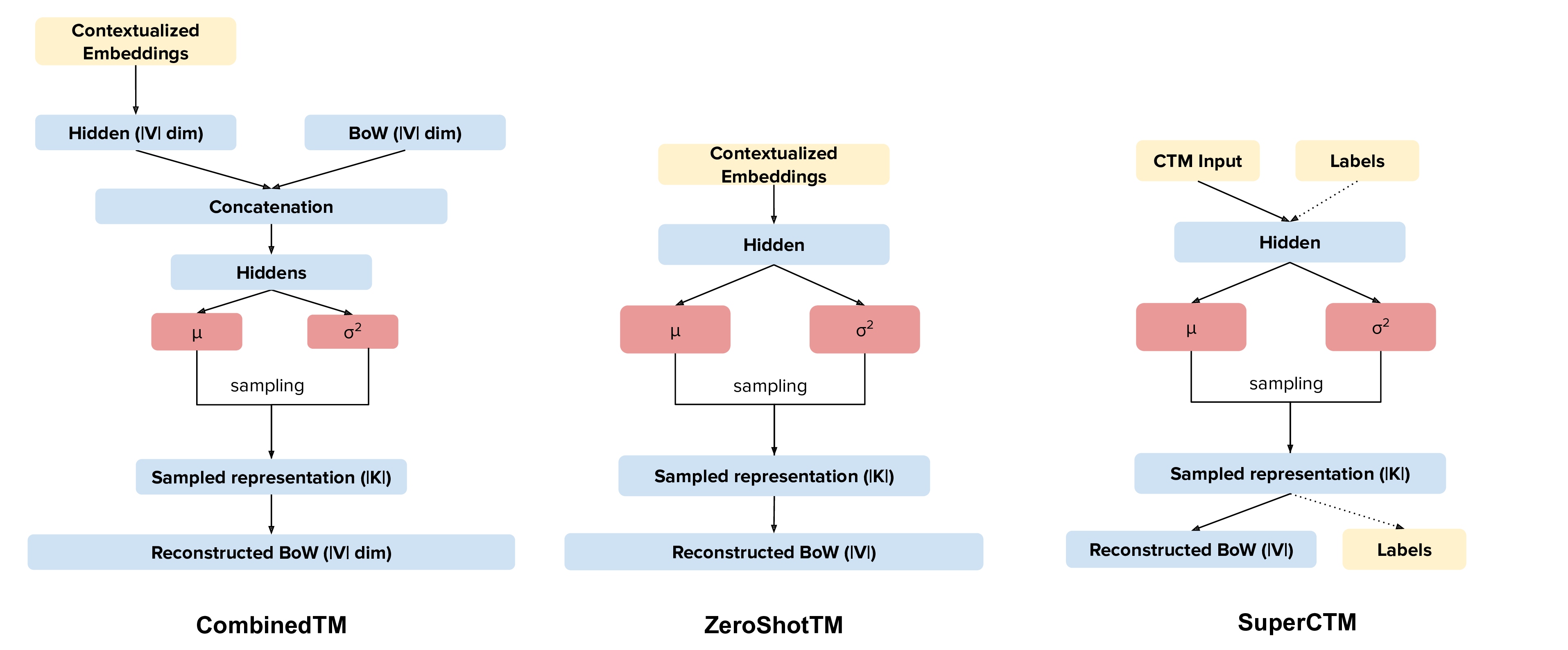
Our new topic modeling family supports many different languages (i.e., the one supported by HuggingFace models) and comes in two versions: CombinedTM combines contextual embeddings with the good old bag of words to make more coherent topics; ZeroShotTM is the perfect topic model for task in which you might have missing words in the test data and also, if trained with multilingual embeddings, inherits the property of being a multilingual topic model!
The big advantage is that you can use different embeddings for CTMs. Thus, when a new embedding method comes out you can use it in the code and improve your results. We are not limited by the BoW anymore.
An important aspect to take into account is which network you want to use: the one that combines contextualized embeddings and the BoW (CombinedTM) or the one that just uses contextualized embeddings (ZeroShotTM).
But remember that you can do zero-shot cross-lingual topic modeling only with the ZeroShotTM model.
Contextualized Topic Models also support supervision (SuperCTM).
We also have Kitty: a new submodule you can use to create a human-in-the-loop classifier to quickly classify your documents and create named clusters. This can be very useful to do document filtering. It also works in cross-lingual setting and thus you might be able to filter documents in a language you don’t know!
Repository README.md includes links to four Google Colab tutorial notebooks.
CUDA GPU support via PyTorch.
skweak

Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
skweak (pronounced /skwi:k/) is a Python-based software toolkit that provides a concrete solution to this problem using weak supervision. skweak is built around a very simple idea: Instead of annotating texts by hand, we define a set of labelling functions to automatically label our documents, and then aggregate their results to obtain a labelled version of our corpus.
The labelling functions may take various forms, such as domain-specific heuristics (like pattern-matching rules), gazetteers (based on large dictionaries), machine learning models, or even annotations from crowd-workers. The aggregation is done using a statistical model that automatically estimates the relative accuracy (and confusions) of each labelling function by comparing their predictions with one another.
skweak can be applied to both sequence labelling and text classification, and comes with a complete API that makes it possible to create, apply and aggregate labelling functions with just a few lines of code. The toolkit is also tightly integrated with SpaCy, which makes it easy to incorporate into existing NLP pipelines. Give it a try!
Medical Imaging
Python
MedicalZooPytorch
A 3D multi-modal medical image segmentation library in PyTorch
Includes quick-start guide and Colab tutorial notebook.