Background/Theory
StatQuest with Josh Starmer (YouTube)
Statistics, Machine Learning and Data Science can sometimes seem like very scary topics, but since each technique is really just a combination of small and simple steps, they are actually quite simple. My goal with StatQuest is to break down the major methodologies into easy to understand pieces. That said, I don’t dumb down the material. Instead, I build up your understanding so that you are smarter.
Notable Playlists:
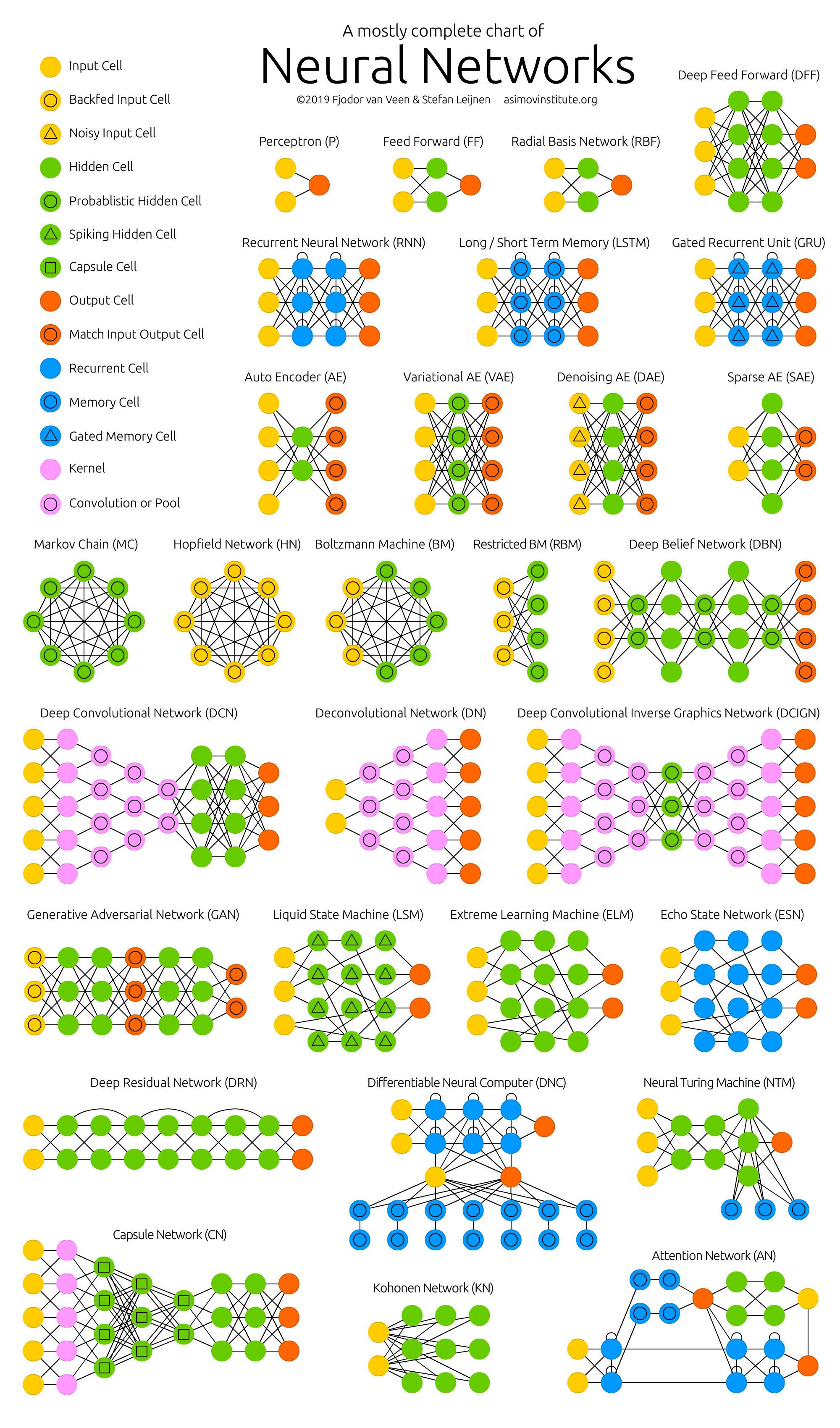
The Asimov Institute’s Neural Network Zoo
Provides cheat sheets depicting various types of neural network architectures and their components (included below). Also contains brief, entry-level descriptions of each type and links to relevant publications (not shown below; please visit the corresponding webpage to view the full contents).

Free Online Books, Handbooks, and Guides
Tim-R413’s Deep Learning Handbook
Start Machine Learning
{{#embed https://youtube/RirEw-uaS_8}}
This guide is intended for anyone having zero or a small background in programming, maths, and machine learning. There is no specific order to follow, but a classic path would be from top to bottom. If you don’t like reading books, skip it, if you don’t want to follow an online course, you can skip it as well. There is not a single way to become a machine learning expert and with motivation, you can absolutely achieve it.
All resources listed here are free, except some online courses and books, which are certainly recommended for a better understanding, but it is definitely possible to become an expert without them, with a little more time spent on online readings, videos and practice. When it comes to paying courses, the links in this guide are affiliated links. Please, use them if you feel like following a course as it will support me. Thank you, and have fun learning! Remember, this is completely up to you and not necessary. I felt like it was useful to me and maybe useful to others as well.
Designing ML Systems summary
A detailed summary of Designing Machine Learning Systems by Chip Huyen. This book gives you an end-to-end view of all the steps required to build AND OPERATE ML products in production. It is a must-read for ML practitioners and Software Engineers transitioning into ML.
Infographic and Diagram Collections
Collections of Visuals and Educational Graphics
The AI Summer’s Deep Learning Visuals

DAIR.AI’s ML Visuals
Terminology Guides
Machine Learning Glossary
Other Collections
gmihaila’s ML Things
This is where I put things I find useful that speed up my work with Machine Learning. Ever looked in your old projects to reuse those cool functions you created before? Well, this repo is designed to be a Python Library of functions I created in my previous project that can be reused. I also share some Notebooks Tutorials and Python Code Snippets.
| Table of contents | |
|---|---|
| Installation | Details on how to install ml_things. |
| Array Functions | Details on the ml_things array related functions (pad_array, batch_array) |
| Plot Functions | Details on the ml_things plot related functions (plot_array, plot_dict, plot_confusion_matrix) |
| Text Functions | Details on the ml_things text related functions (clean_text) |
| Web Related | Details on the ml_things web related functions (download_from) |
| Snippets | Curated list of Python snippets I frequently use. |
| Comments | Sample on how I like to comment my code. It is still a work in progress. |
| Notebooks Tutorials | Machine learning projects that I converted to tutorials and posted online. |
| Final Note | Being grateful. |
nivu’s AI All Resources
Example Neural Network Architecture Collections
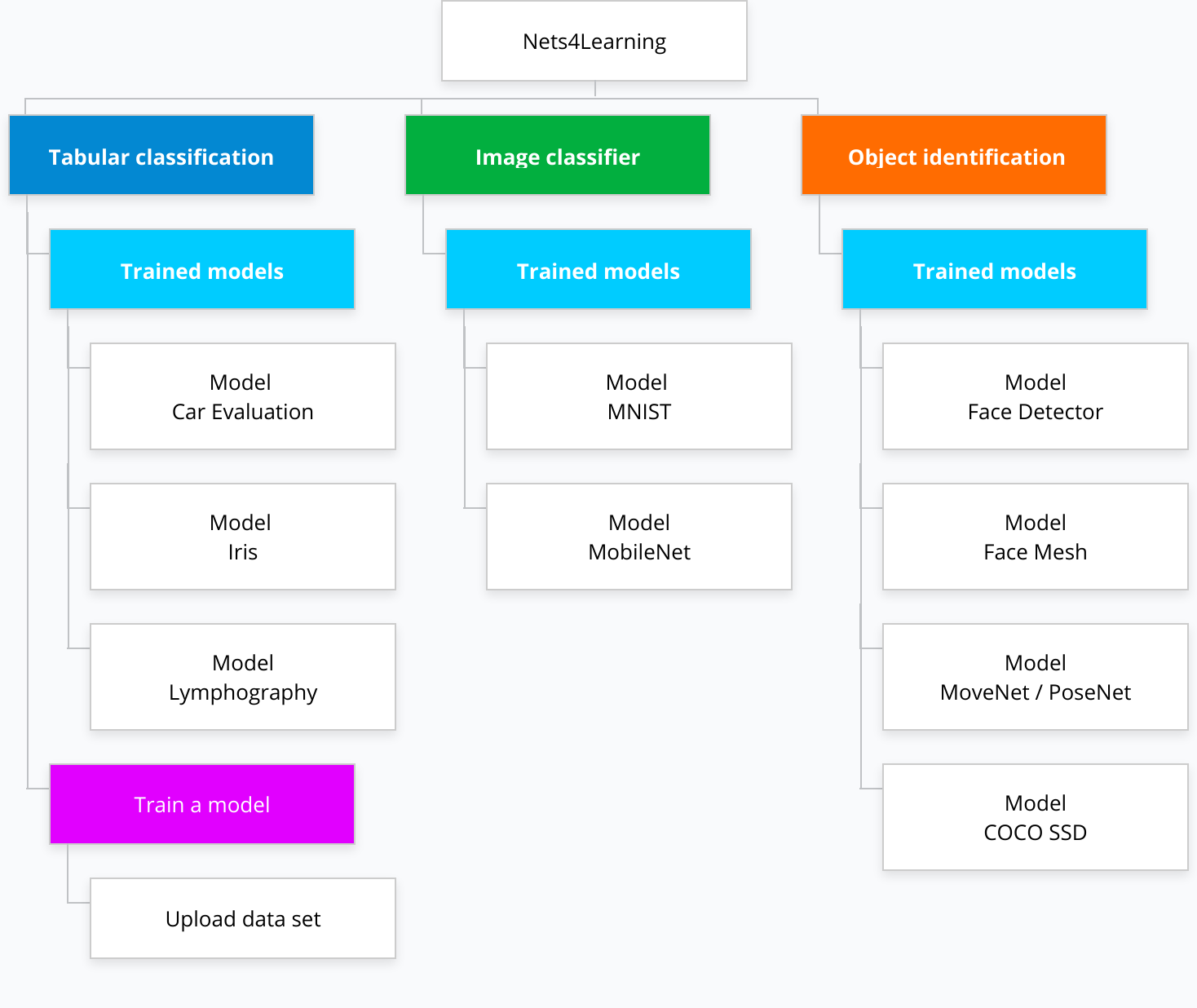
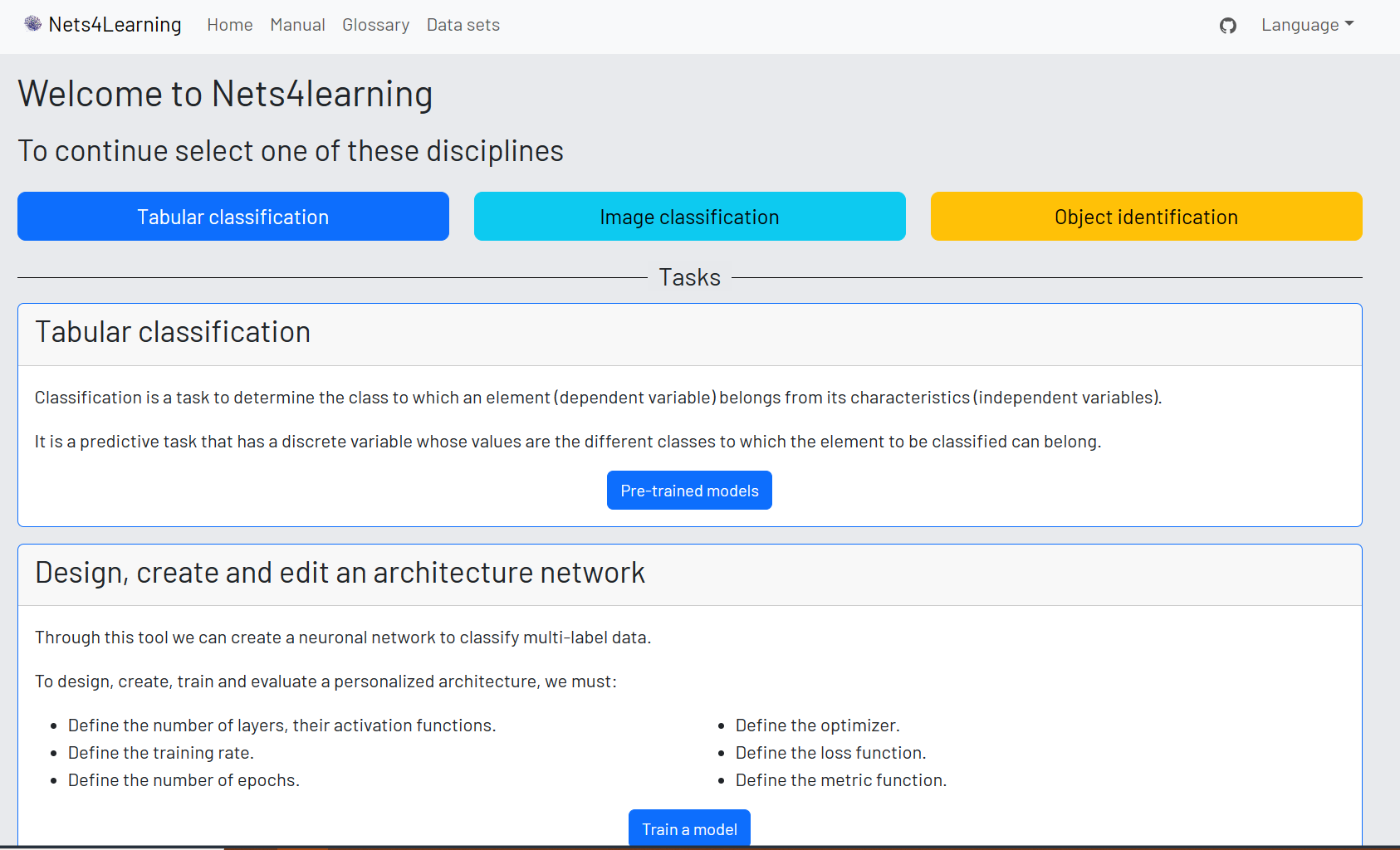
Nets4Learning
The tool proposes different classical machine learning problems with known data sets to study and model different neural network architectures and training parameters. The tool addresses different examples of deep learning models such as tabular classification, image classifier or object identification.
There are some classical problems prepared and reviewed to make predictions, the tool has the feature to preprocess data sets that the user uploads, train models and predict in which class it would be classified.
Flux Model Zoo
This repository contains various demonstrations of the Flux machine learning library. Any of these may freely be used as a starting point for your own models.
The models are broadly categorised into the folders vision (e.g. large convolutional neural networks (CNNs)), text (e.g. various recurrent neural networks (RNNs) and natural language processing (NLP) models), games (Reinforcement Learning / RL). See the READMEs of respective models for more information.
Note that Flux is a library written for the Julia programming langauge (i.e. not Python).
Recommended Websites
Articles
distill
Description
Selected Articles
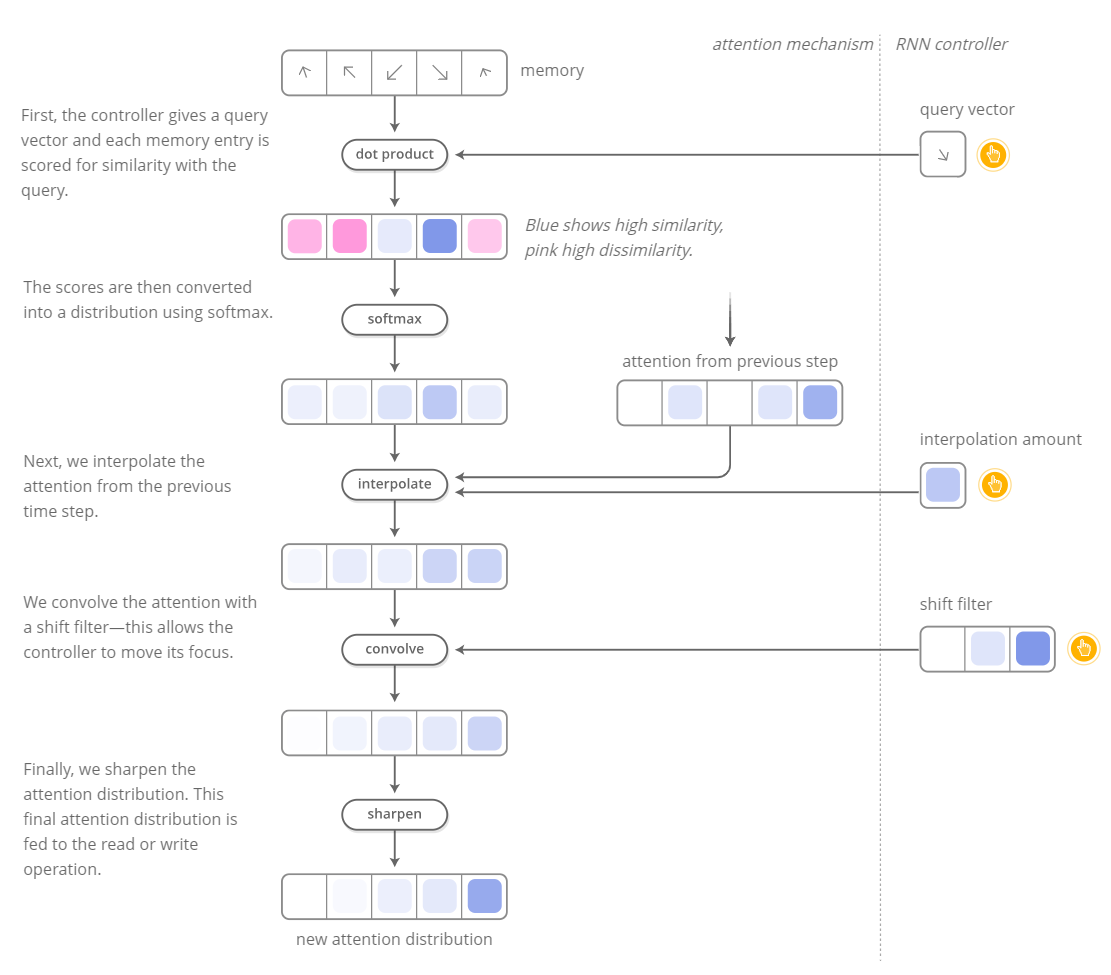
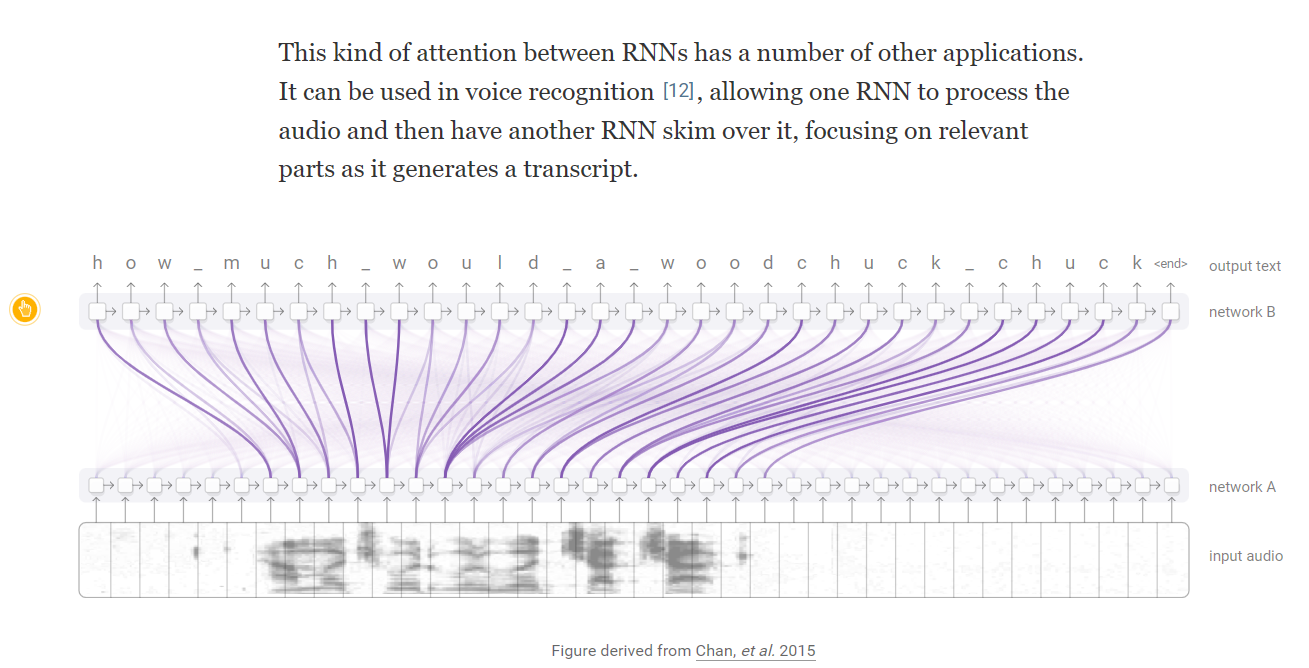
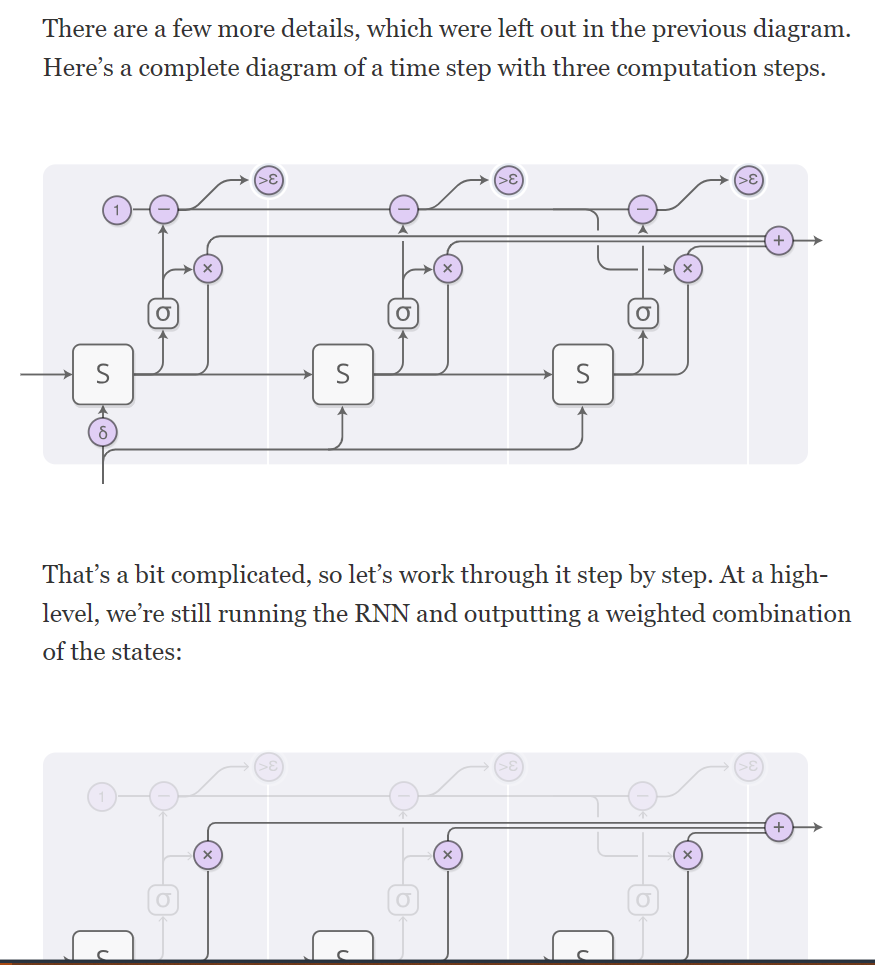
Attention and Augmented Recurrent Neural Networks

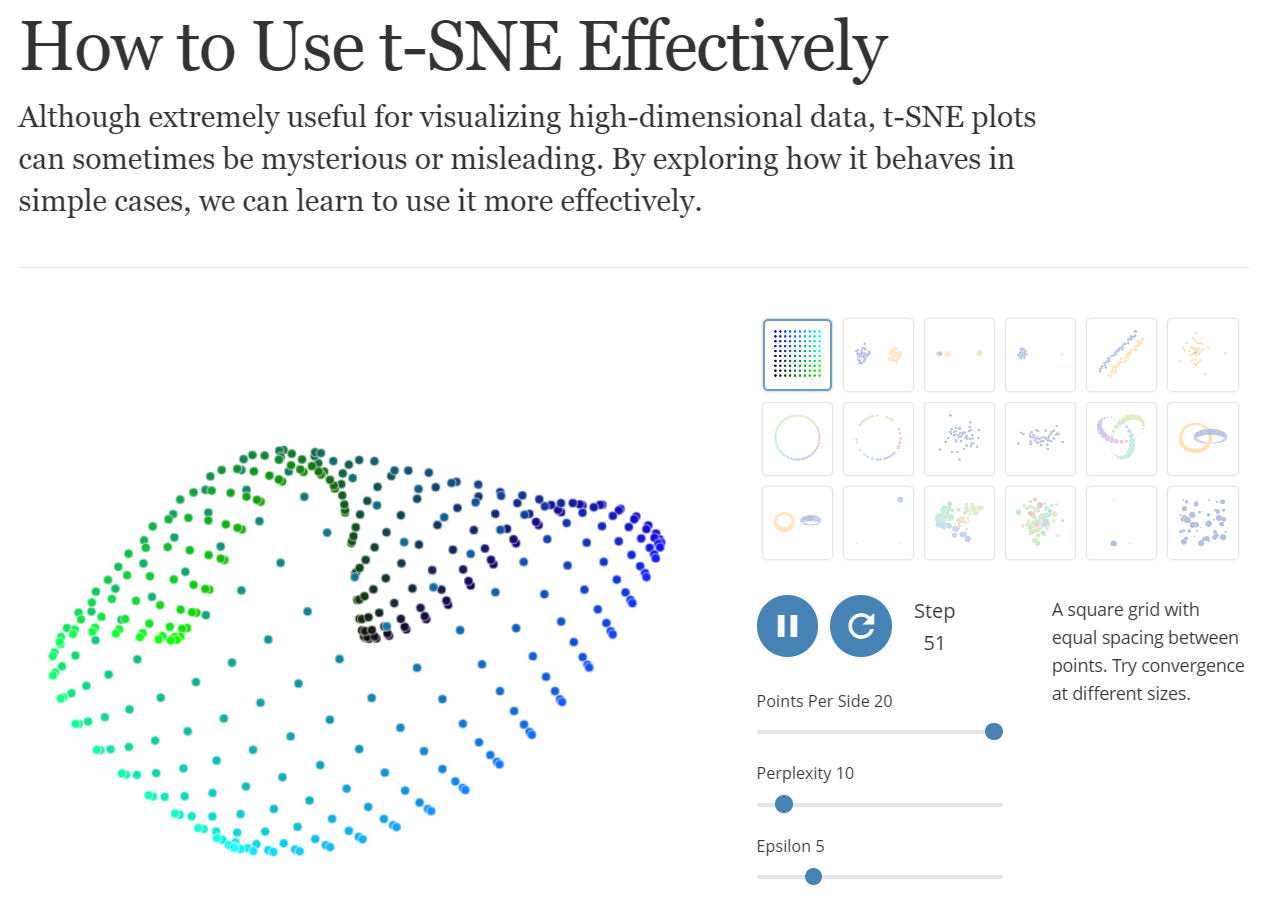
How to Use t-SNE Effectively
Although extremely useful for visualizing high-dimensional data, t-SNE plots can sometimes be mysterious or misleading. By exploring how it behaves in simple cases, we can learn to use it more effectively.
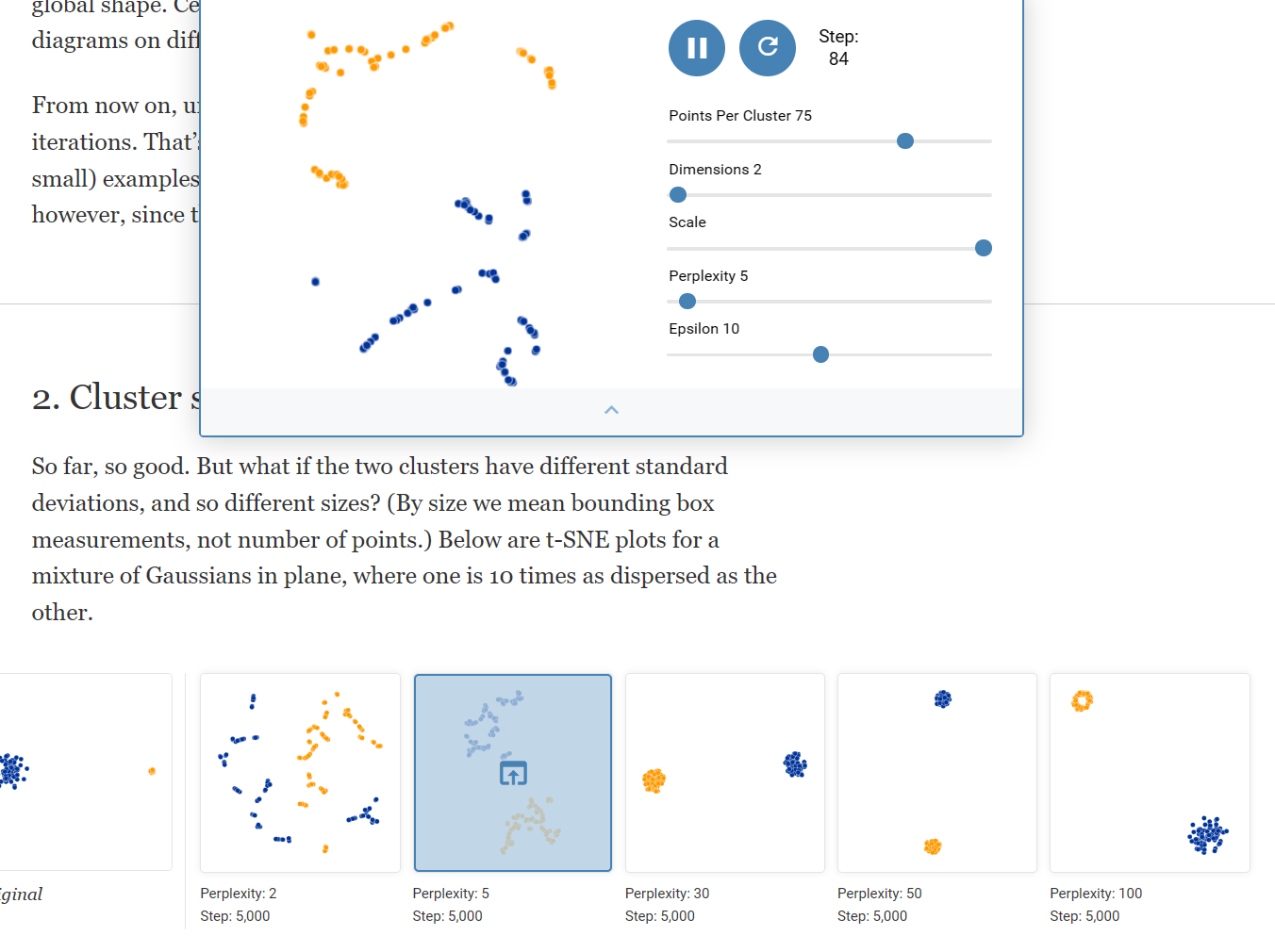
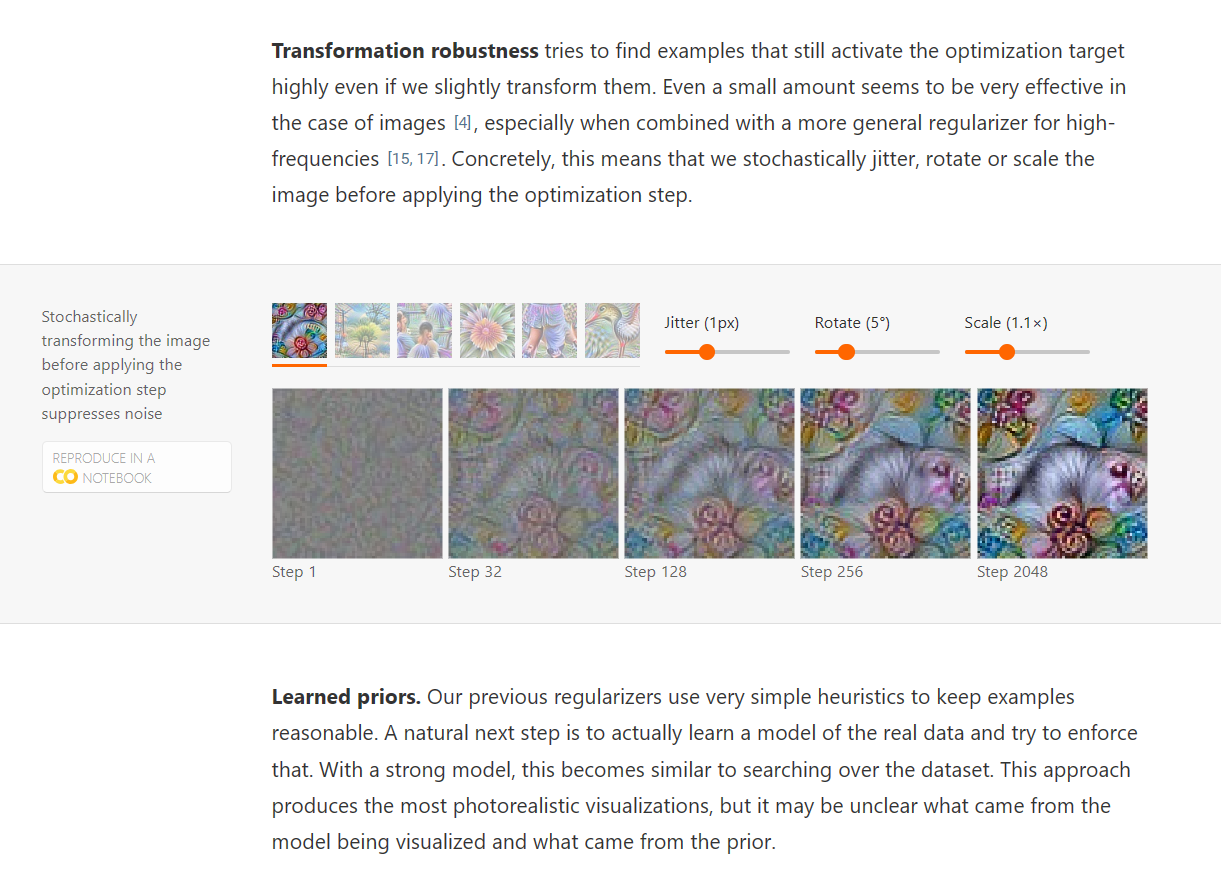
Feature Visualization


Sequence Modeling with CTC




The Building Blocks of Interpretability
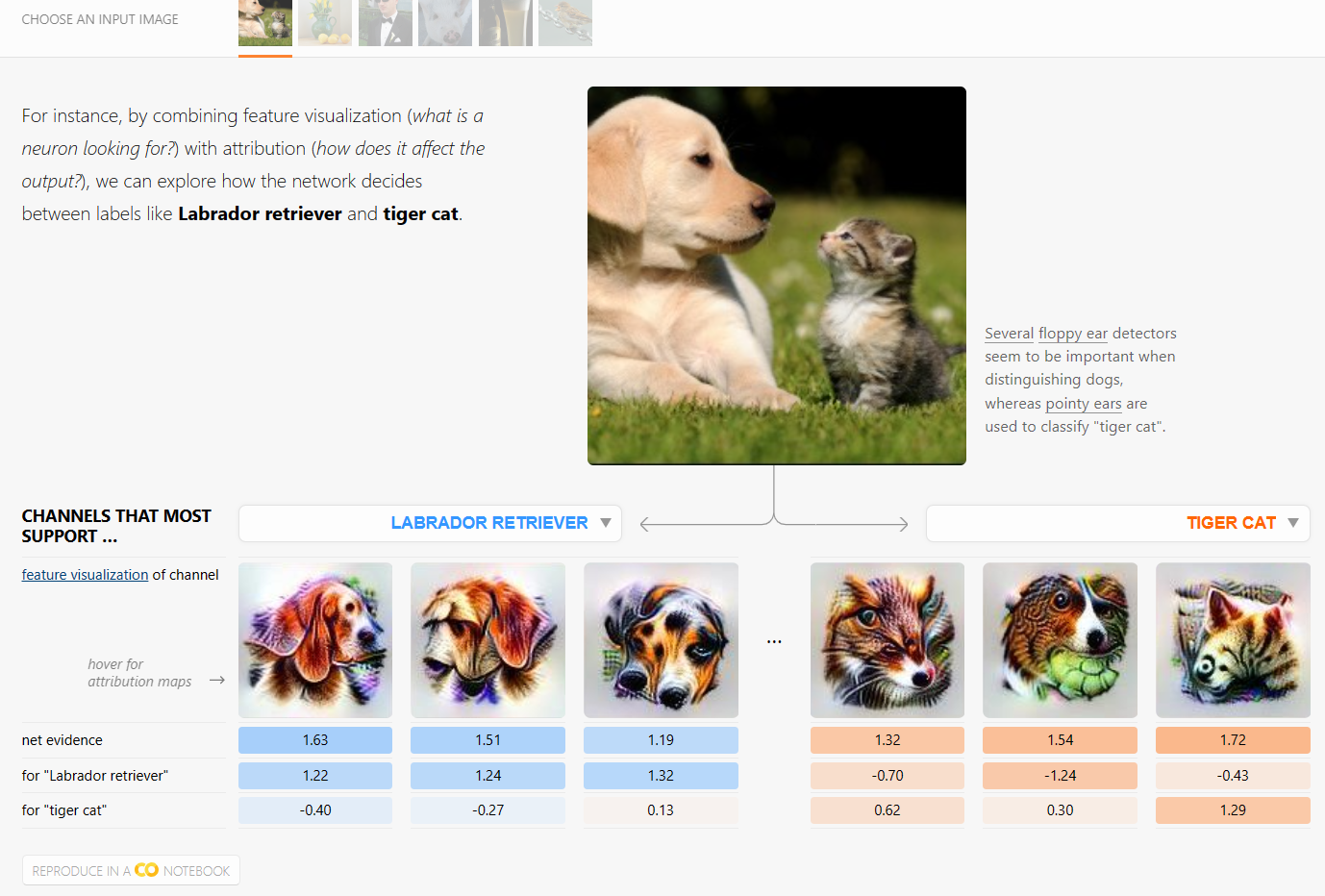
Interpretability techniques are normally studied in isolation. We explore the powerful interfaces that arise when you combine them — and the rich structure of this combinatorial space. For instance, by combining feature visualization (what is a neuron looking for?) with attribution (how does it affect the output?), we can explore how the network decides between labels like Labrador retriever and tiger cat.
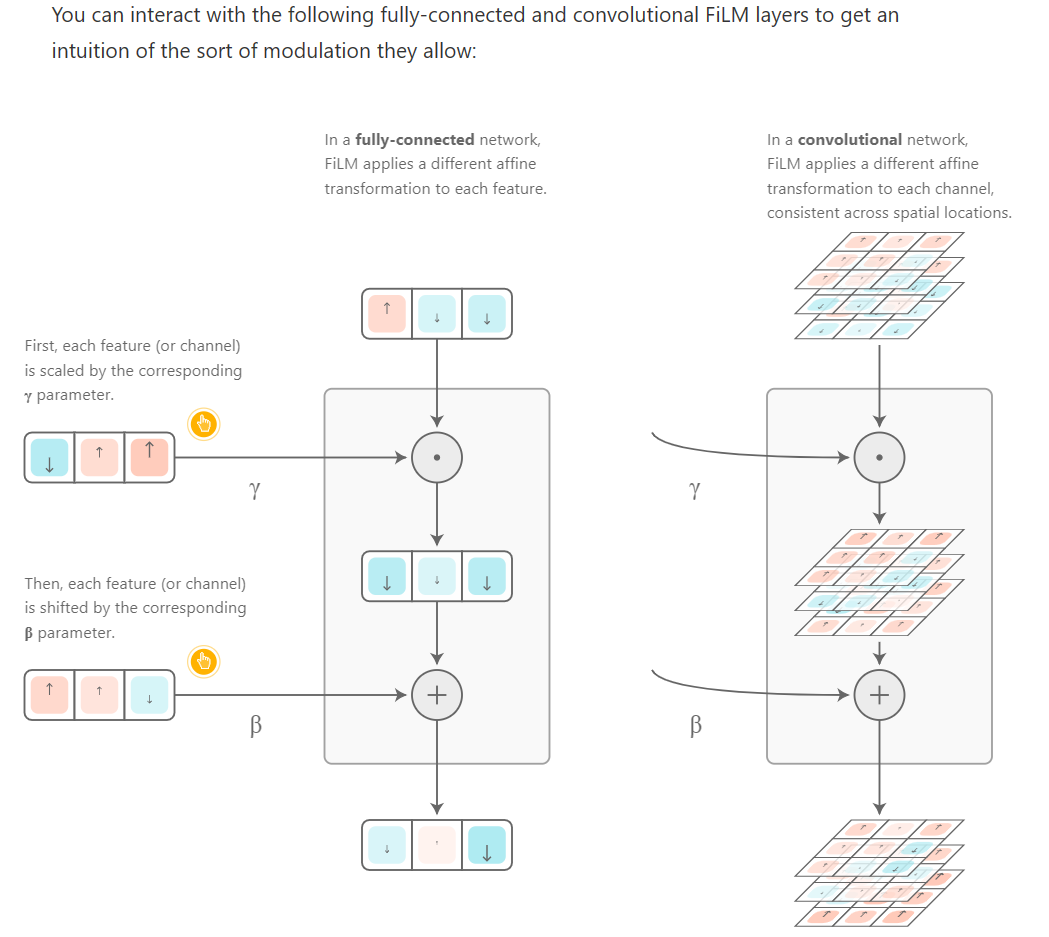
Feature-Wise Transformations
Many real-world problems require integrating multiple sources of information. Sometimes these problems involve multiple, distinct modalities of information — vision, language, audio, etc. — as is required to understand a scene in a movie or answer a question about an image. Other times, these problems involve multiple sources of the same kind of input, i.e. when summarizing several documents or drawing one image in the style of another.
Exploring Neural Networks with Activation Atlases
By using feature inversion to visualize millions of activations from an image classification network, we create an explorable activation atlas of features the network has learned which can reveal how the network typically represents some concepts.

Visualizing memorization in RNNs
This article presents a qualitative visualization method for comparing recurrent units with regards to memorization and contextual understanding. The method is applied to the three recurrent units mentioned above: Nested LSTMs, LSTMs, and GRUs.

Paths Perspective on Value Learning
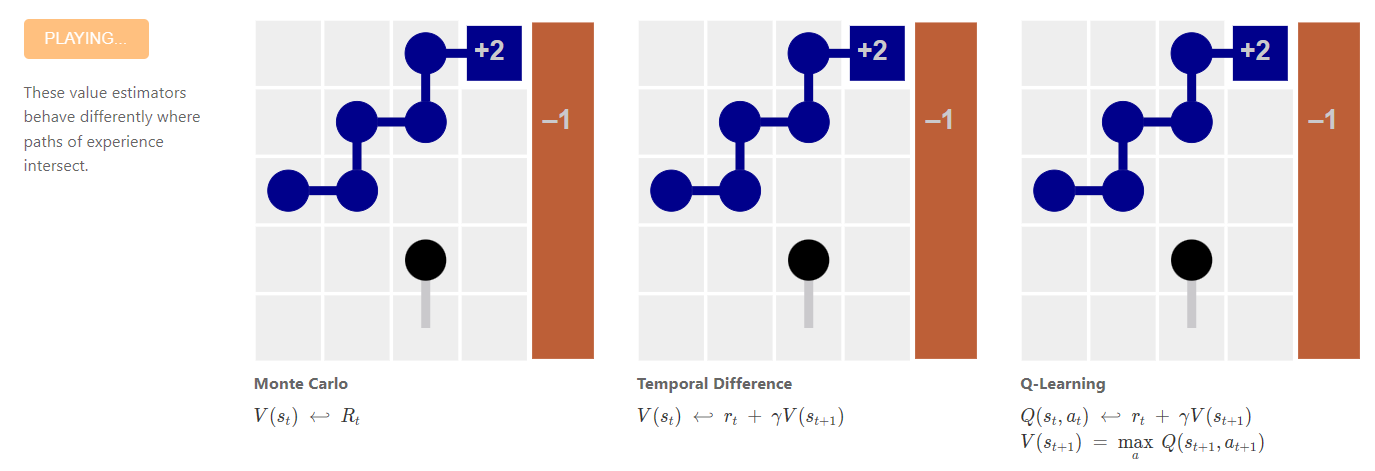
 ::
::
Computing Receptive Fields of Convolutional Neural Networks
<div class="infobox-row"><div class="infobox-head">Tagline</div><div class="infobox-spacer"></div><div class="infobox-tail">Mathematical derivations and <a href="https://github.com/google-research/receptive_field">open-source library</a> to compute receptive fields of convnets, enabling the mapping of extracted features to input signals.</div></div>
<div class="infobox-row"><div class="infobox-head">Link</div><div class="infobox-spacer"></div><div class="infobox-tail"><a href="https://distill.pub/2019/computing-receptive-fields/">https://distill.pub/2019/computing-receptive-fields/</a></div></div>
Visualizing Neural Networks with the Grand Tour
The Grand Tour is a classic visualization technique for high-dimensional point clouds that projects a high-dimensional dataset into two dimensions. Over time, the Grand Tour smoothly animates its projection so that every possible view of the dataset is (eventually) presented to the viewer. …
In this article, we show how to leverage the linearity of the Grand Tour to enable a number of capabilities that are uniquely useful to visualize the behavior of neural networks.
Concretely, we present three use cases of interest:
- visualizing the training process as the network weights change,
- visualizing the layer-to-layer behavior as the data goes through the network[,] and
- visualizing both how adversarial examples are crafted and how they fool a neural network.
Understanding RL (Reinforcement Learning) Vision
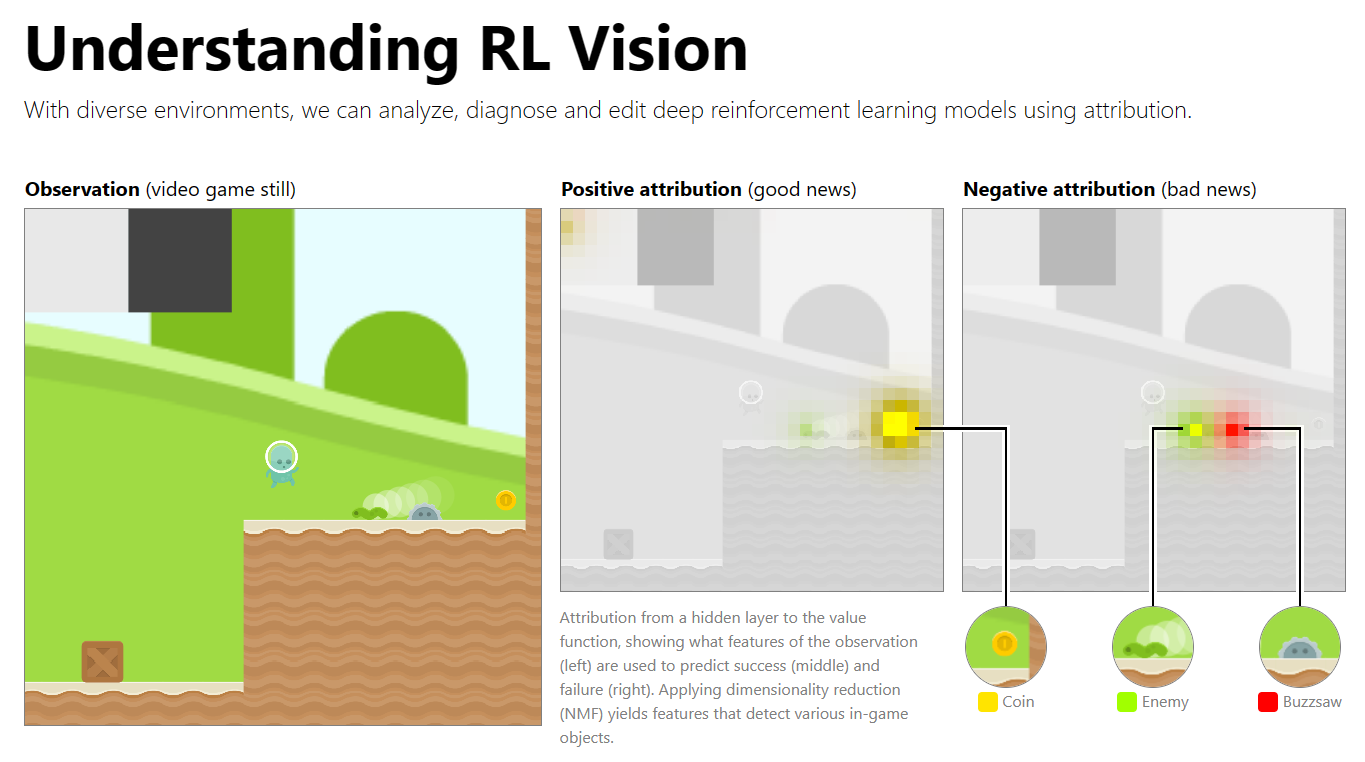
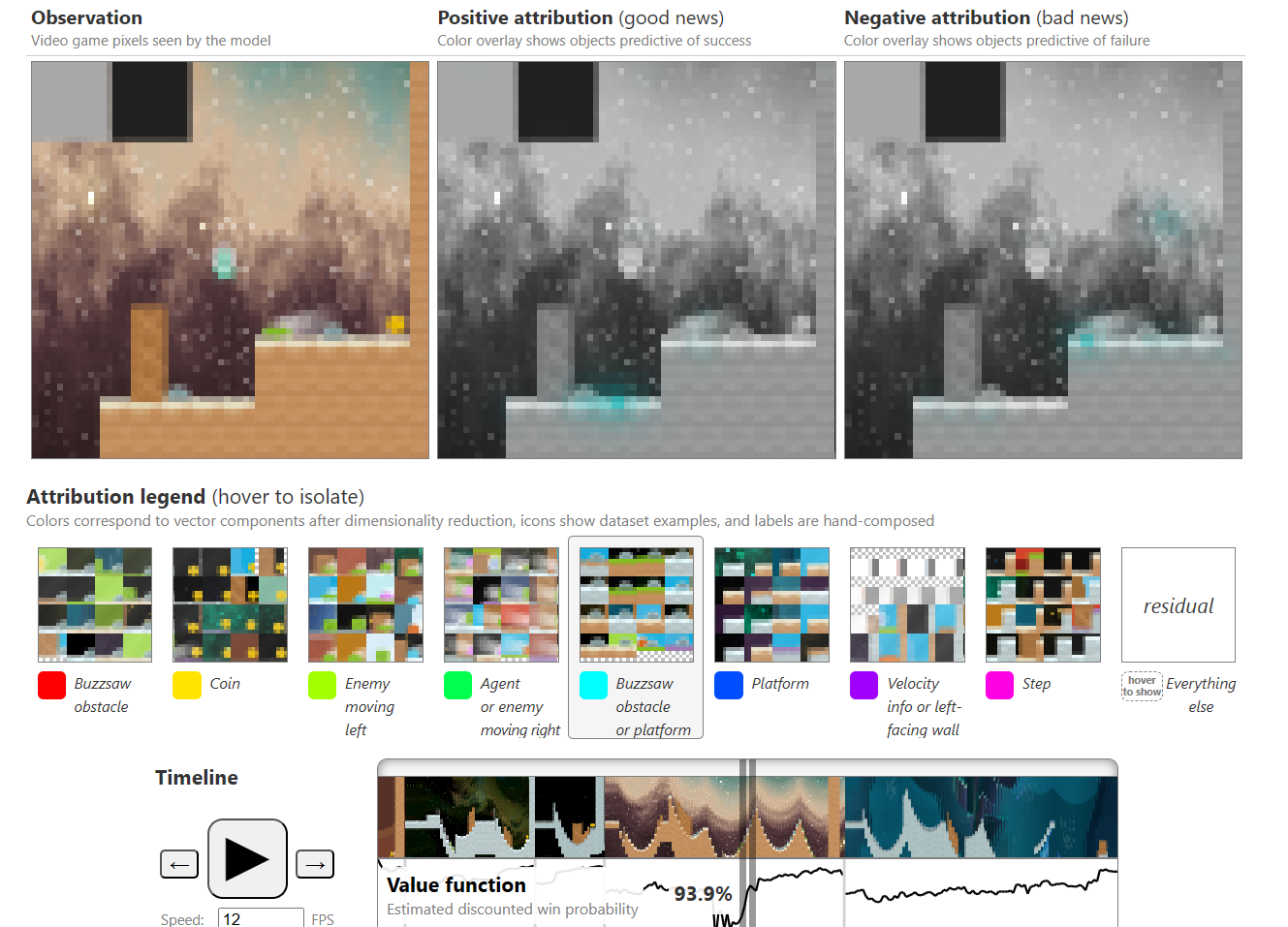
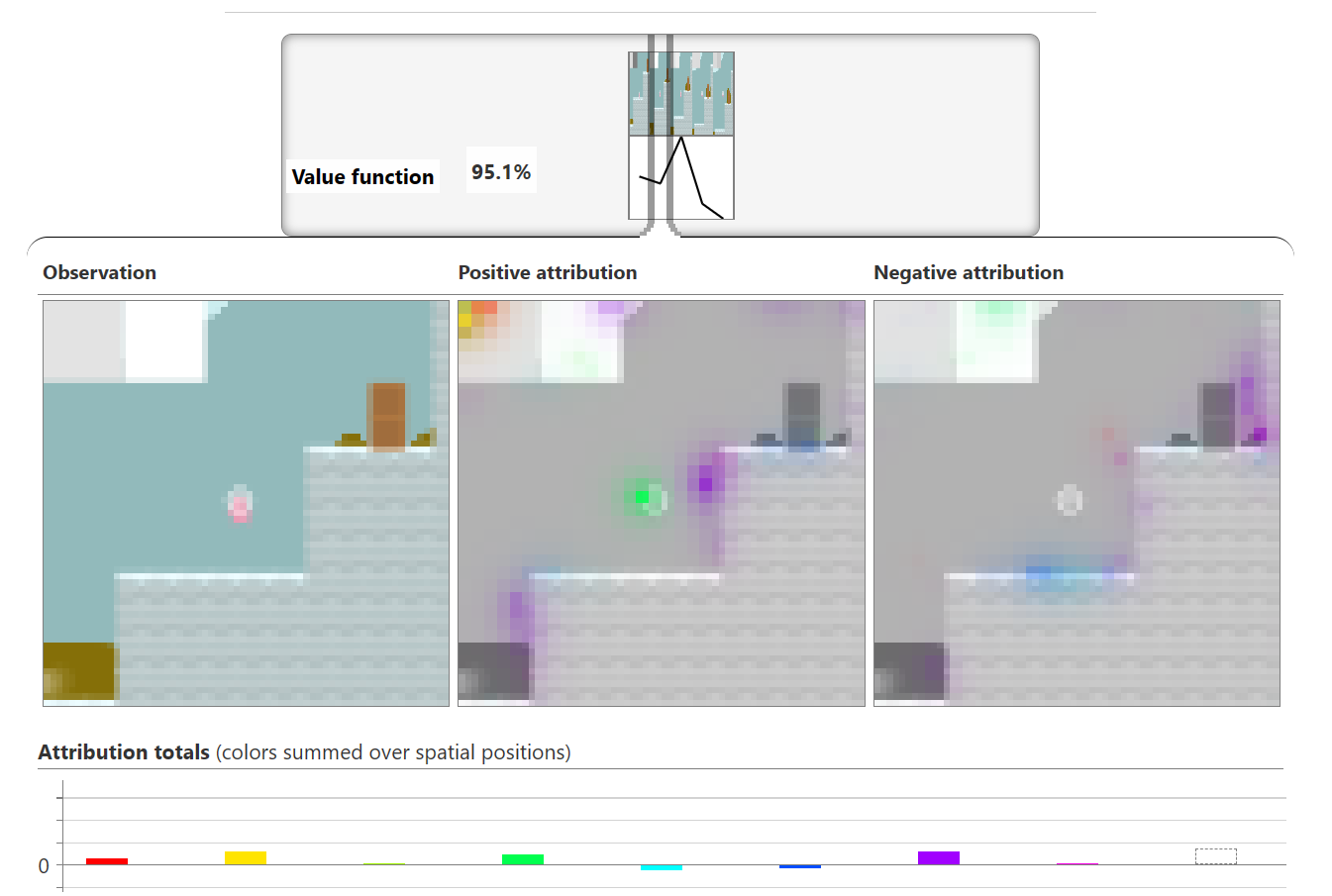

Demos and Playgrounds
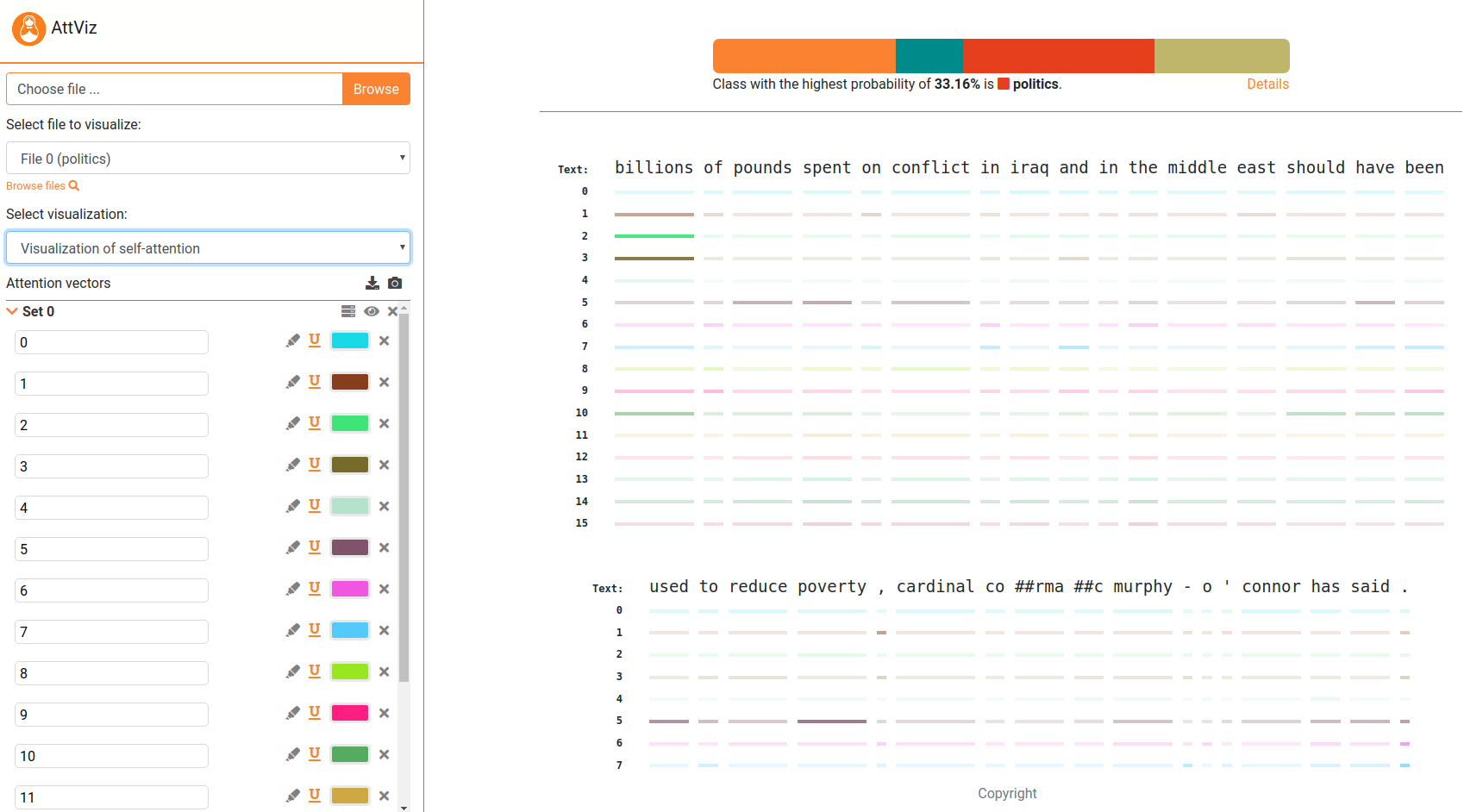
Attention Visualization
AttViz
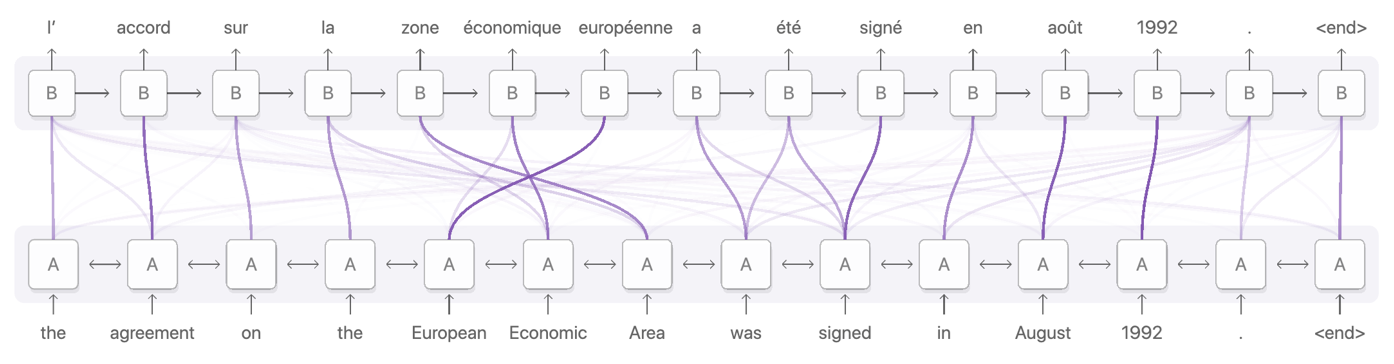
BertViz
BertViz is an interactive tool for visualizing attention in Transformer language models such as BERT, GPT2, or T5. It can be run inside a Jupyter or Colab notebook through a simple Python API that supports most Huggingface models. BertViz extends the Tensor2Tensor visualization tool by Llion Jones, providing multiple views that each offer a unique lens into the attention mechanism.
The repository link contains information about usage as well as several links to interactive tutorial Colab notebooks.
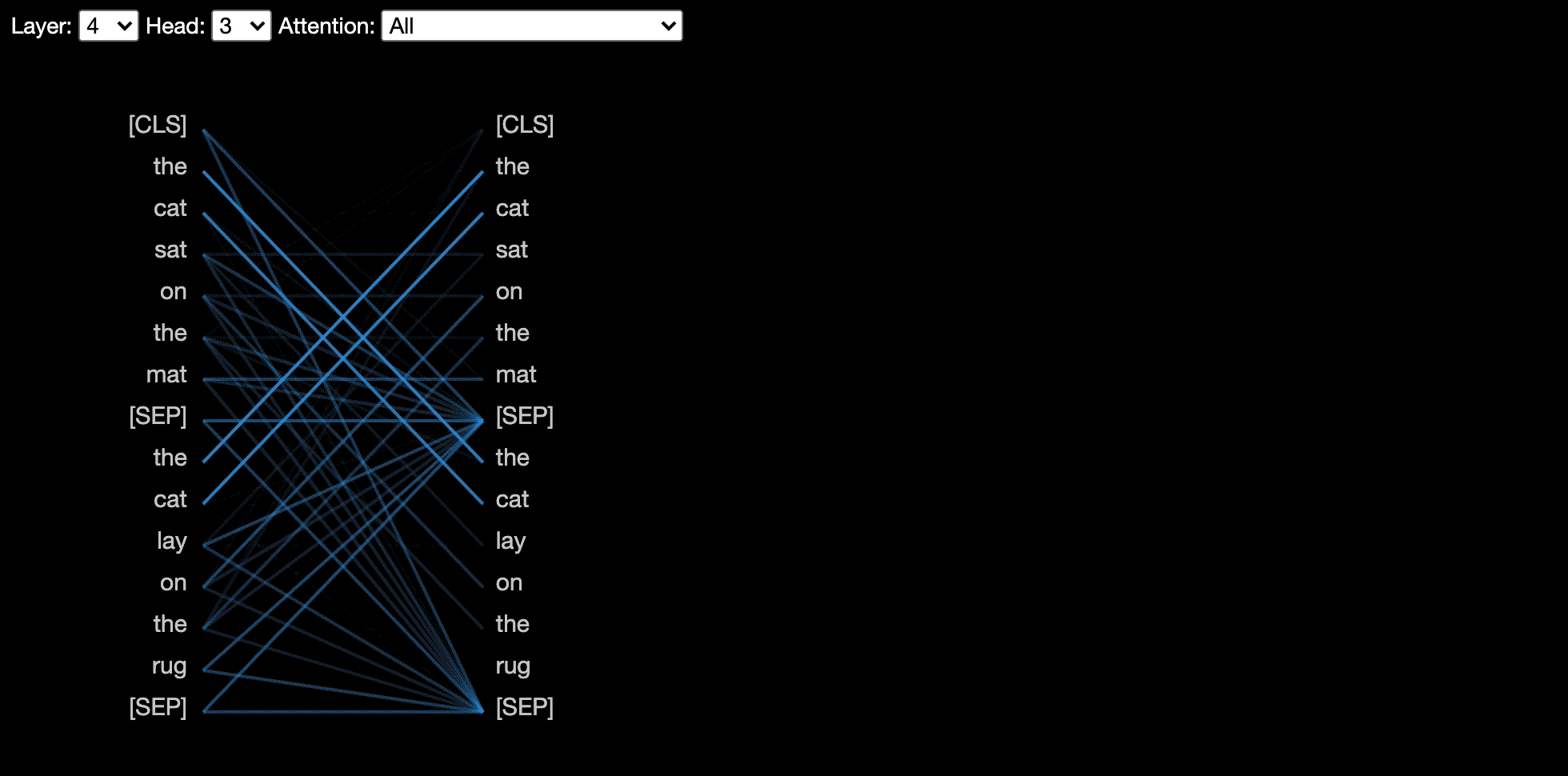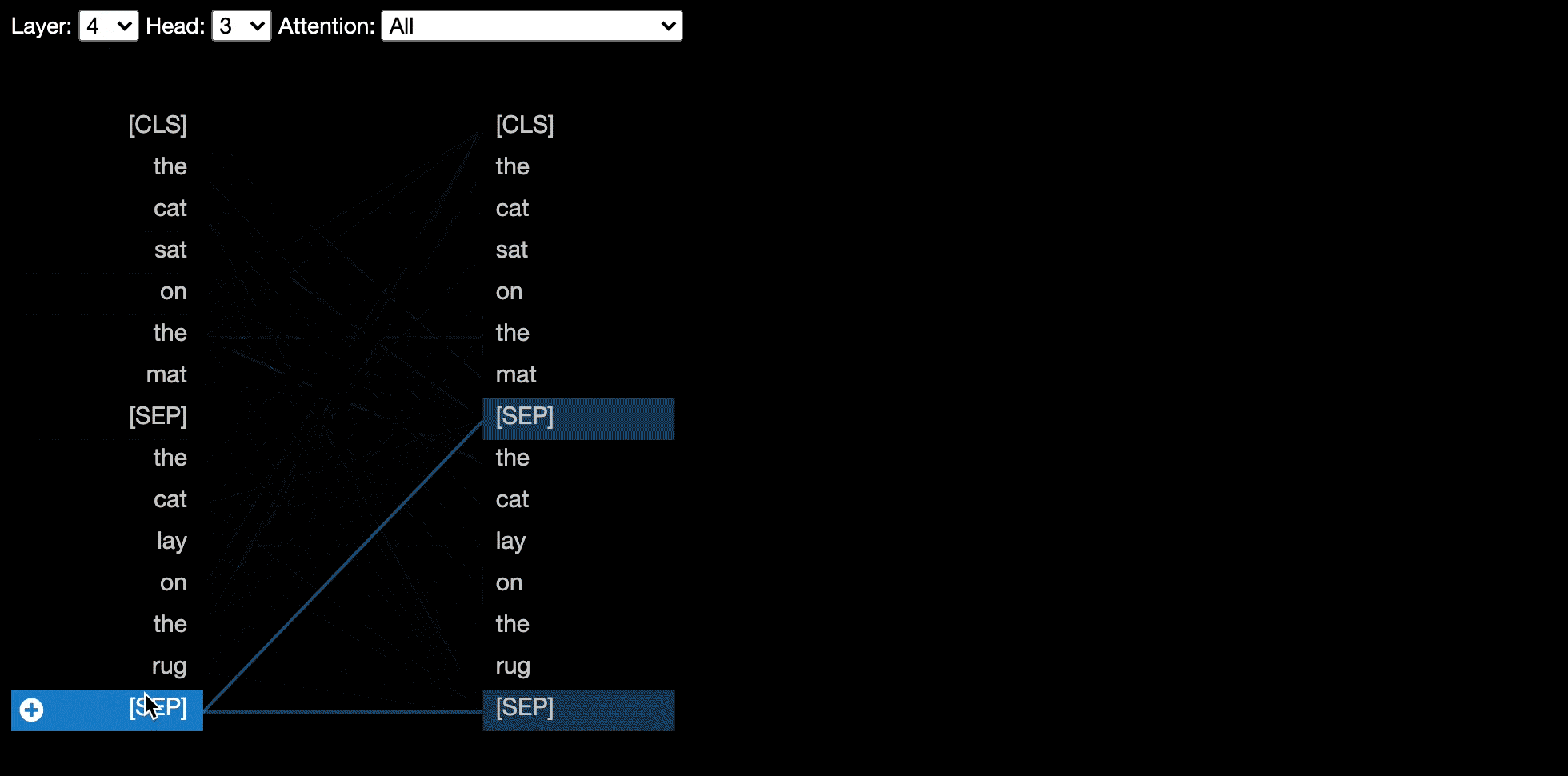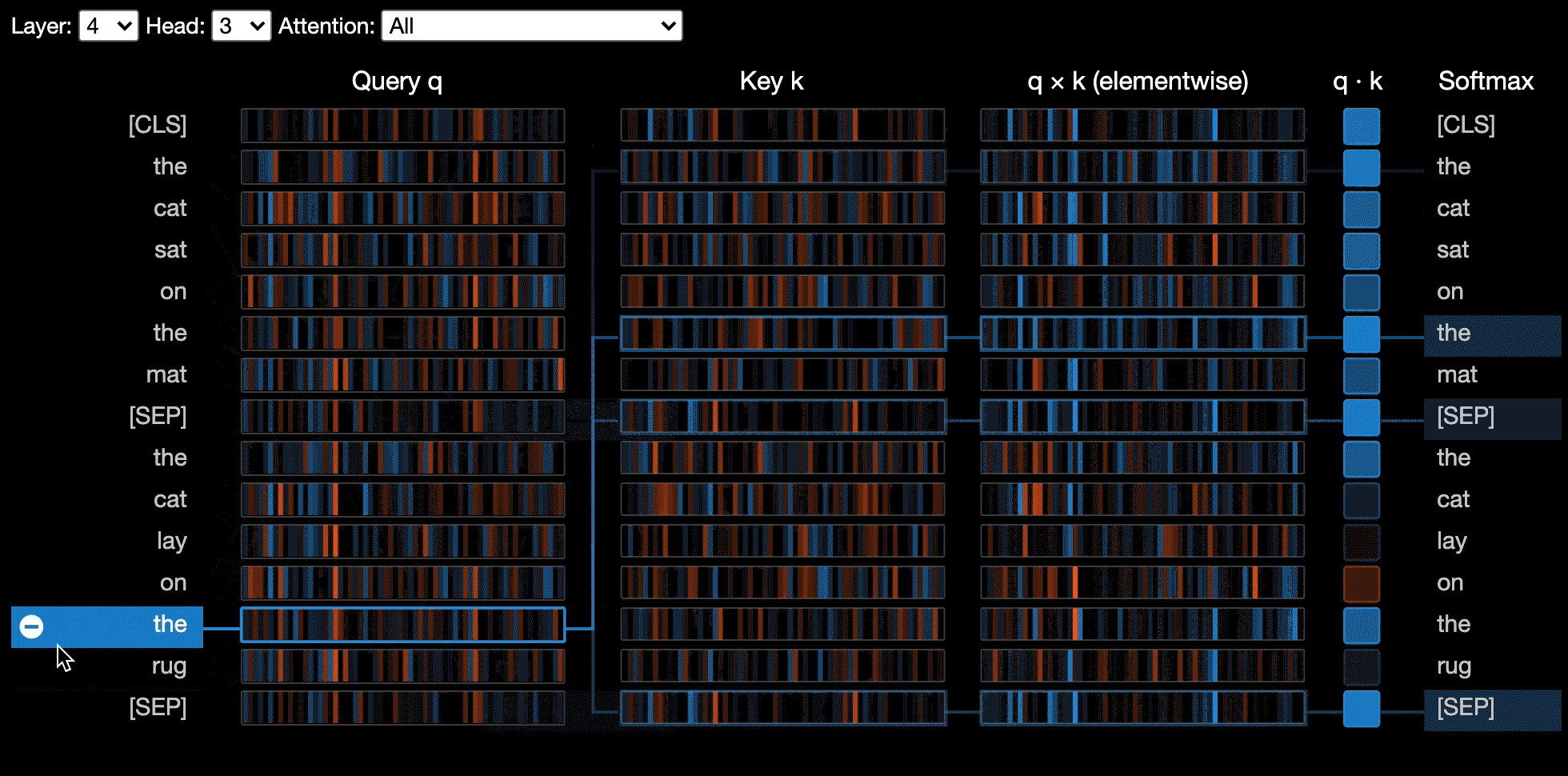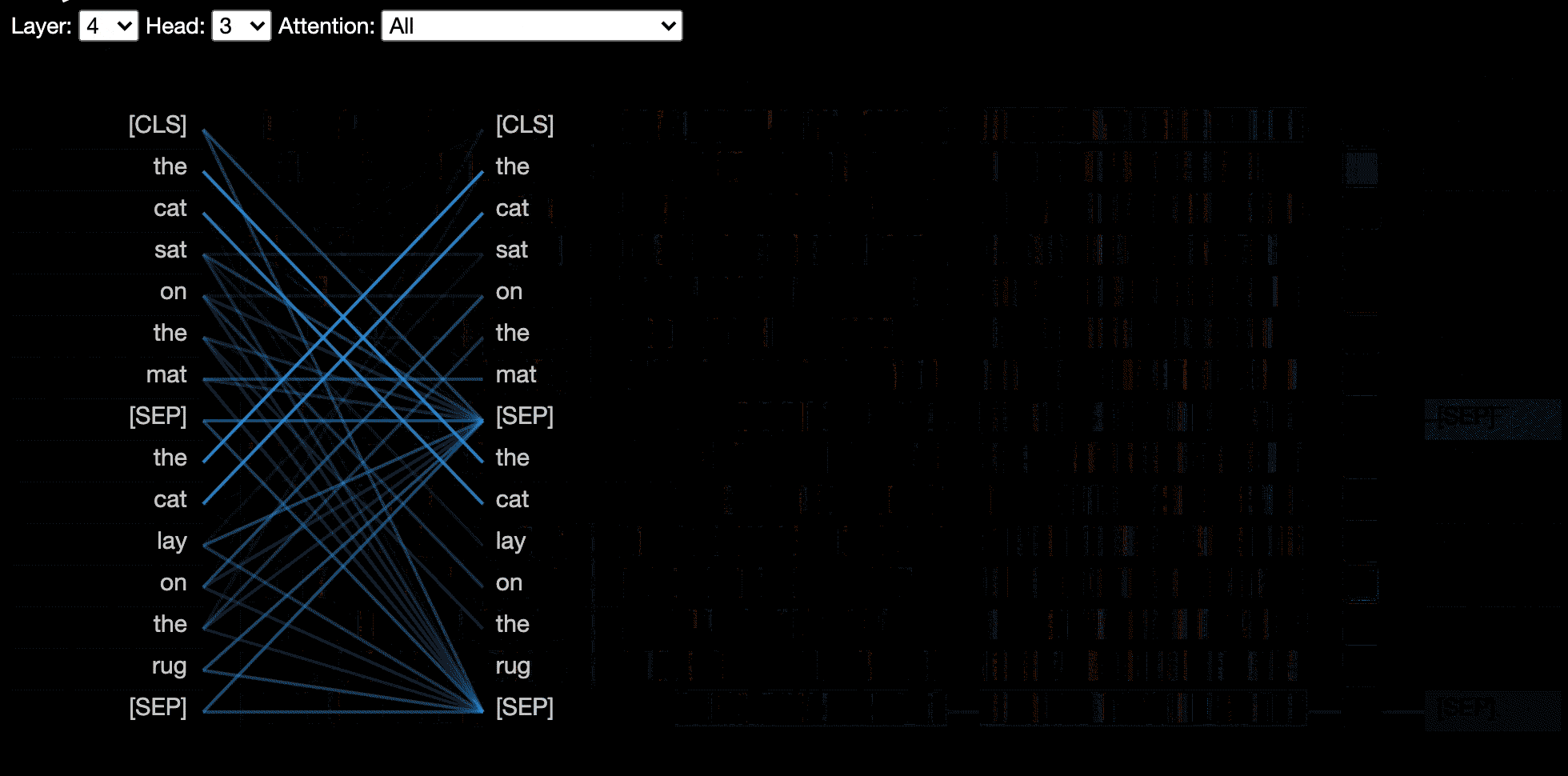

attention-viz
Attention Viz is an interactive tool that visualizes global attention patterns for transformer models. To create this tool, we visualize the joint embeddings of query and key vectors.
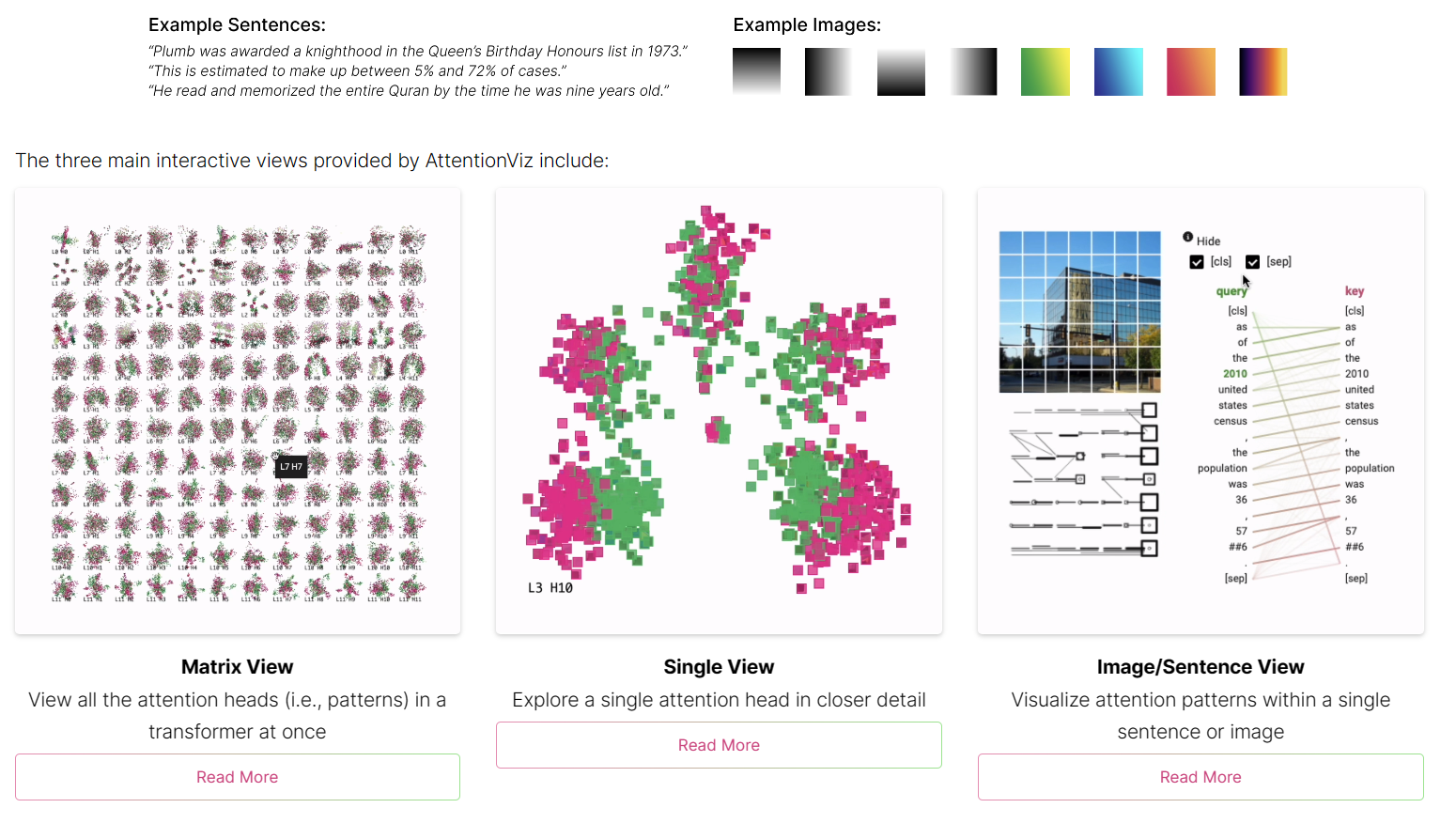

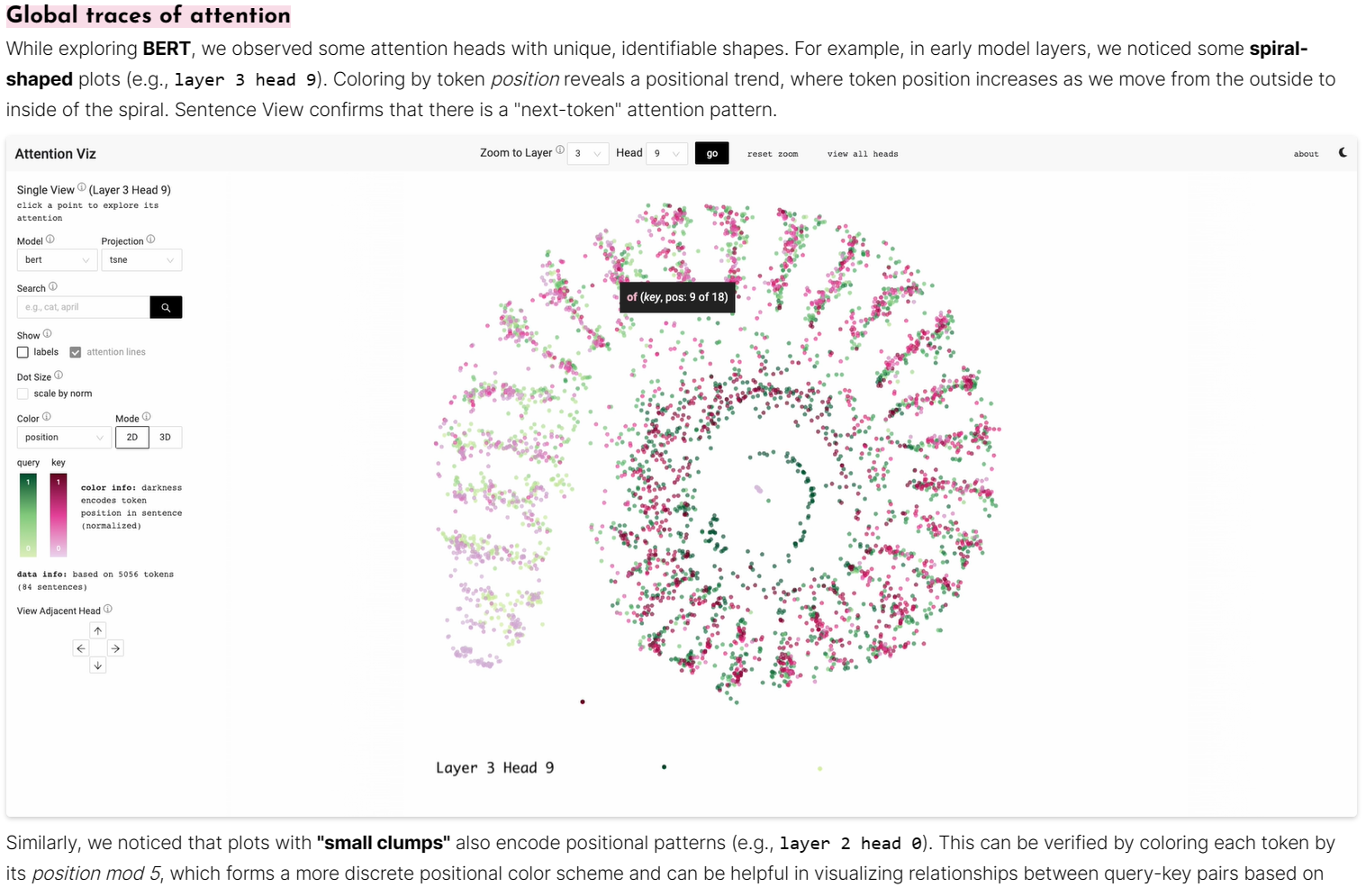
attentions
| Implementation List | |
|---|---|
| Name | Citation |
| Additive attention | Bahdanau et al., 2015 |
| Dot-product attention | Luong et al., 2015 |
| Location-Aware (Location Sensitive) Attention | Chorowski et al., 2015 |
| Scaled Dot-Product Attention | Vaswani et al., 2017 |
| Multi-Head Attention | Vaswani et al., 2017 |
| Relative Multi-Head Self Attention | ZihangDai et al., 2019 |
Other
Anomagram
Anomagram is an interactive experience built with Tensorflow.js to demonstrate how deep neural networks (autoencoders) can be applied to the task of anomaly detection.
DRLViz
VisualML
Visual Machine Learning contains a set of Machine Learning and Deep Learning interactive visualisation demos for developing intuition. These demos are developed using TensorFlow.js and can be executed directly in your browser.
Live demo links:
RNN Explainer
(Recommendation: “try this demo with a screen which is larger than 8 inches and has a minimum resolution of 1280x720”)
CNN Explainer
An interactive visualization system designed to help non-experts learn about Convolutional Neural Networks (CNNs)
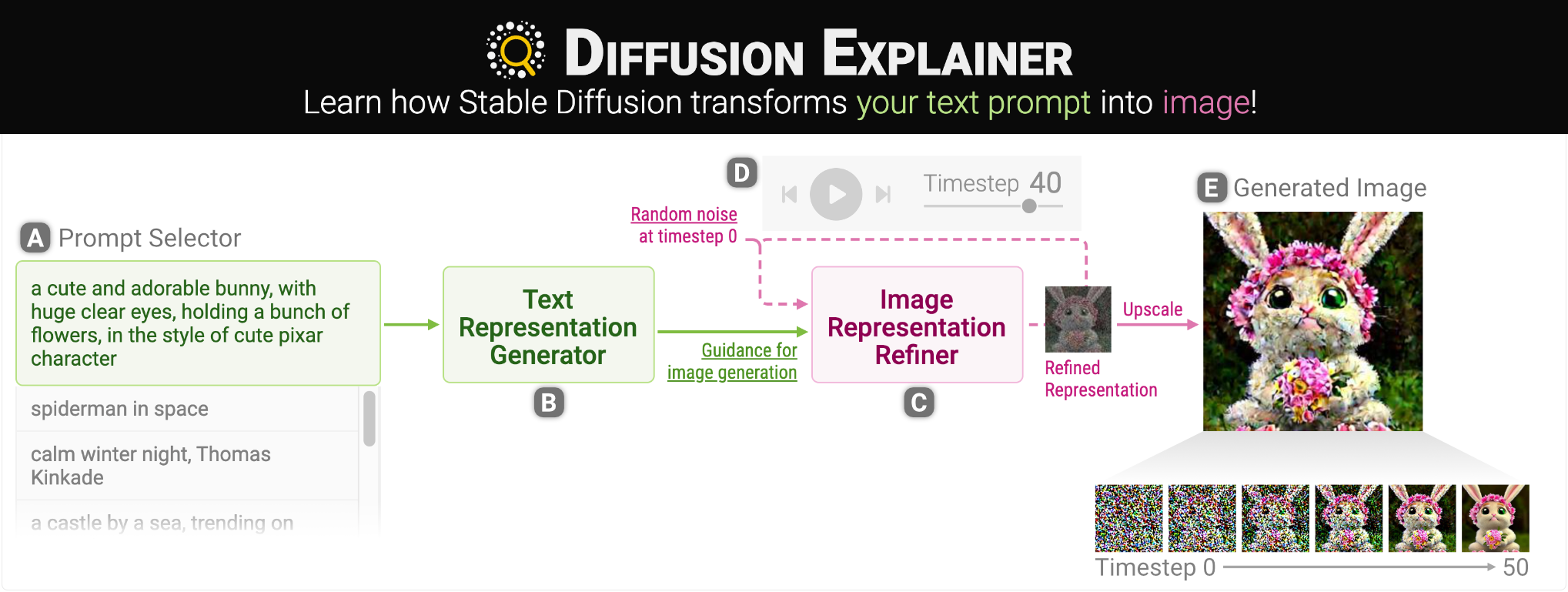
Diffusion Explainer
Wizmap
The repository includes an interactive notebook containing instructions for using your own embeddings with WizMap.
WizMap is a scalable interactive visualization tool to help you easily explore large machine learning embeddings. With a novel multi-resolution embedding summarization method and a familiar map-like interaction design, WizMap allows you to navigate and interpret embedding spaces with ease.

 |
 |
 |
| DiffusionDB Prompts + Images | ACL Paper Abstracts | IMDB Review Comments |
| 1.8M text + 1.8M images | 63k text | 25k text |
CLIP Embedding |
all-MiniLM-L6-v2 Embedding |
all-MiniLM-L6-v2 Embedding |
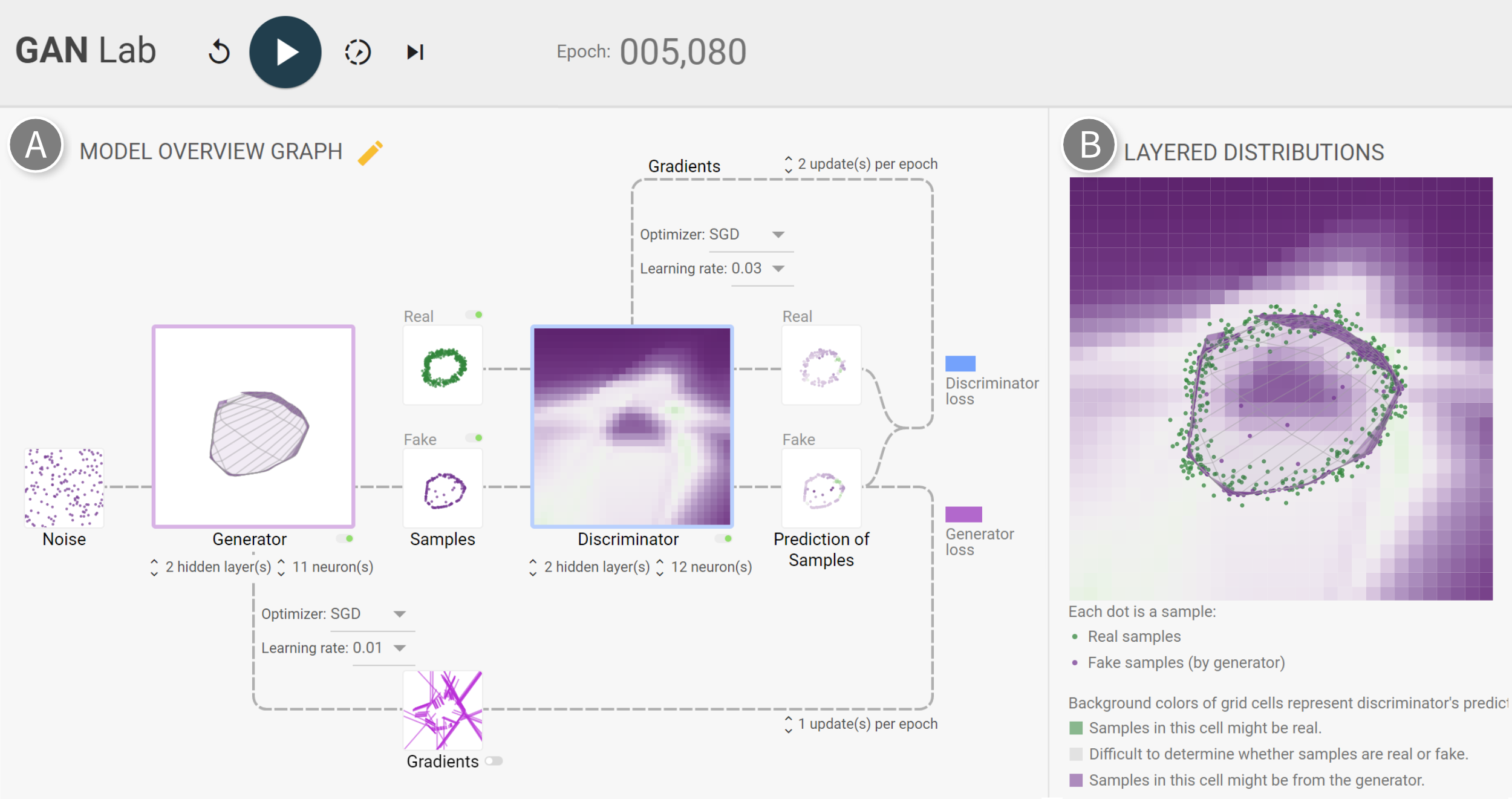
GanLab
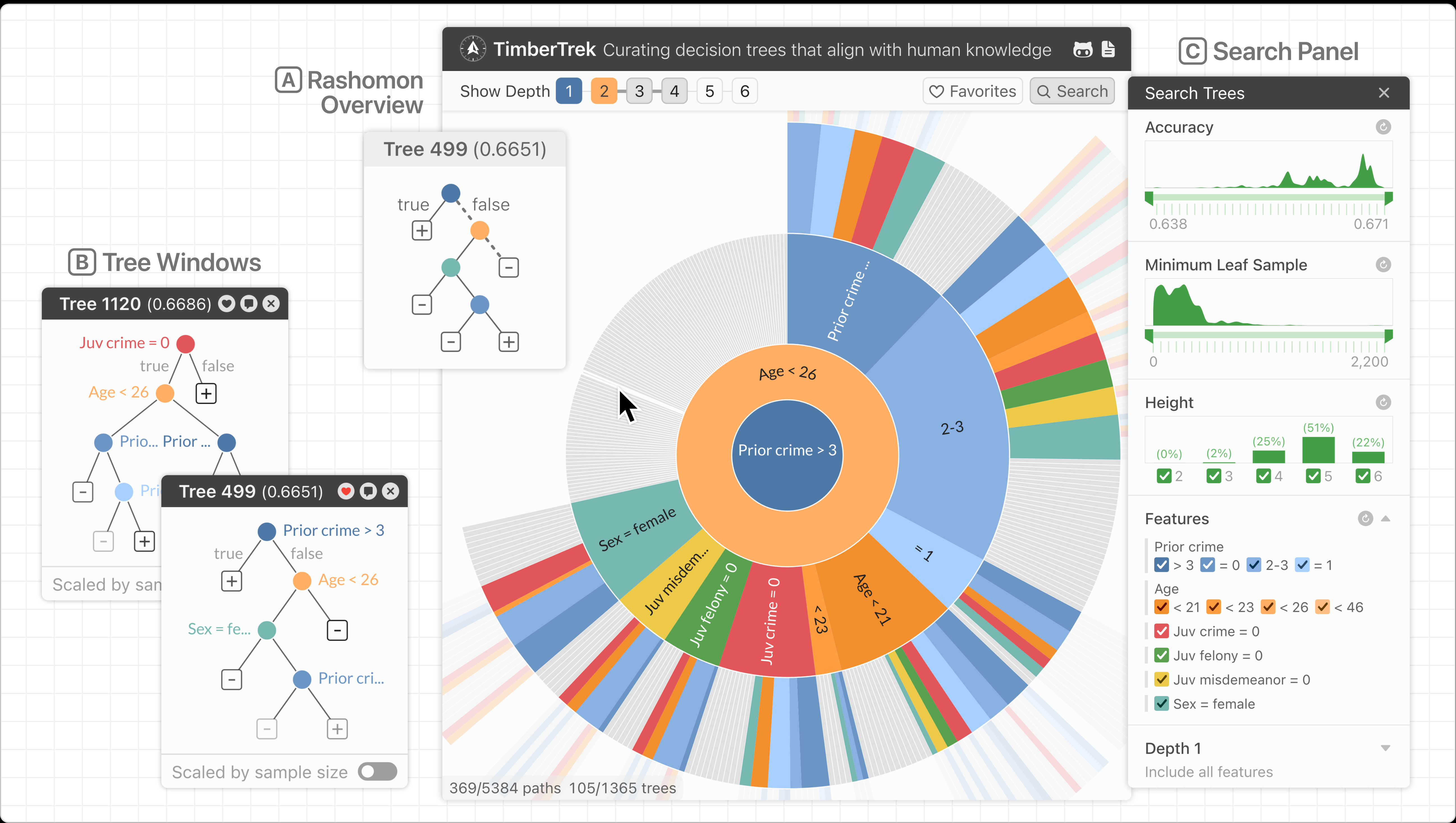
TimberTrek
GAM Coach

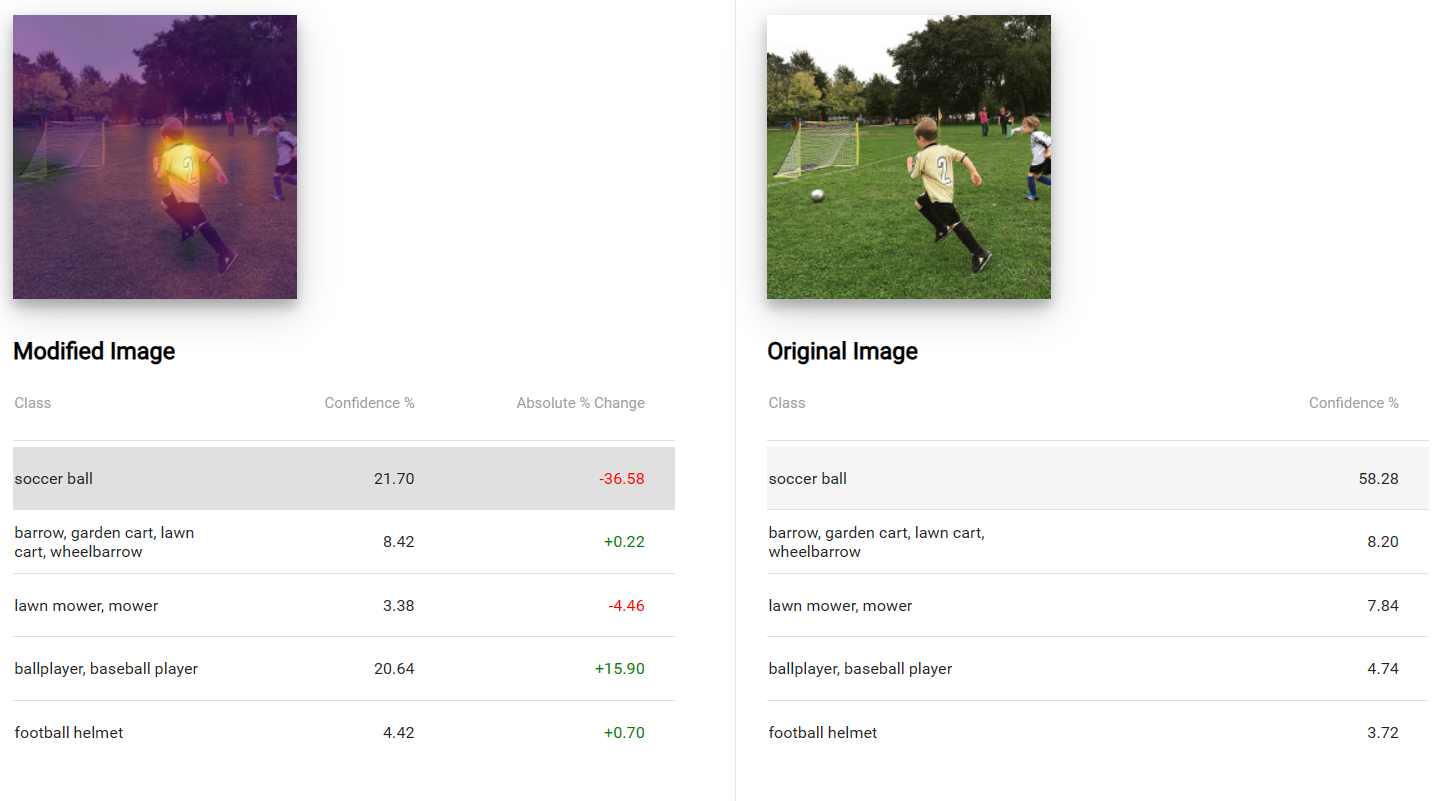
Interactive Classification
The live demo includes a “tour”-style tutorial.
Interactive Classification allows you to explore how computers see by modifying images.

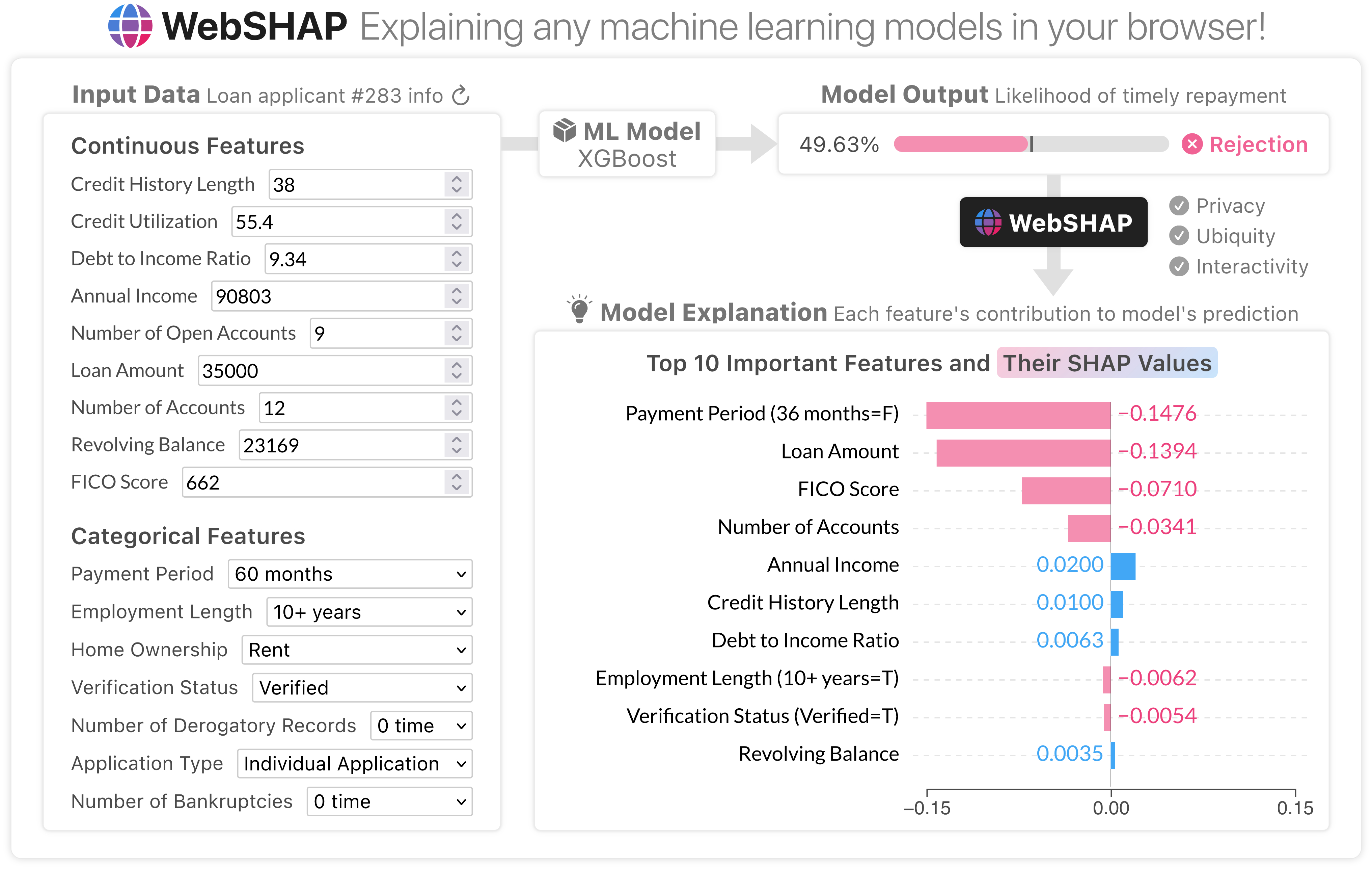
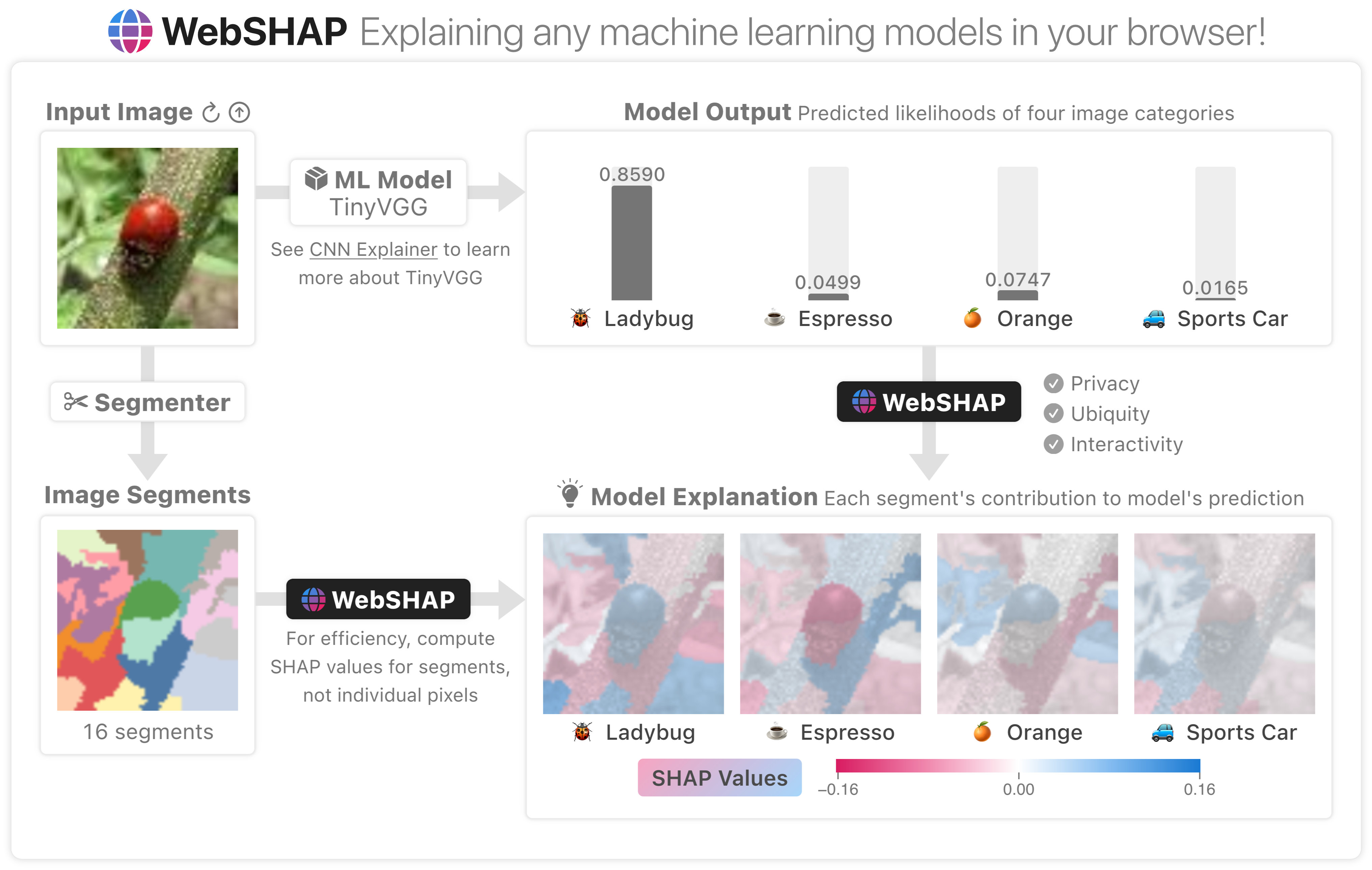
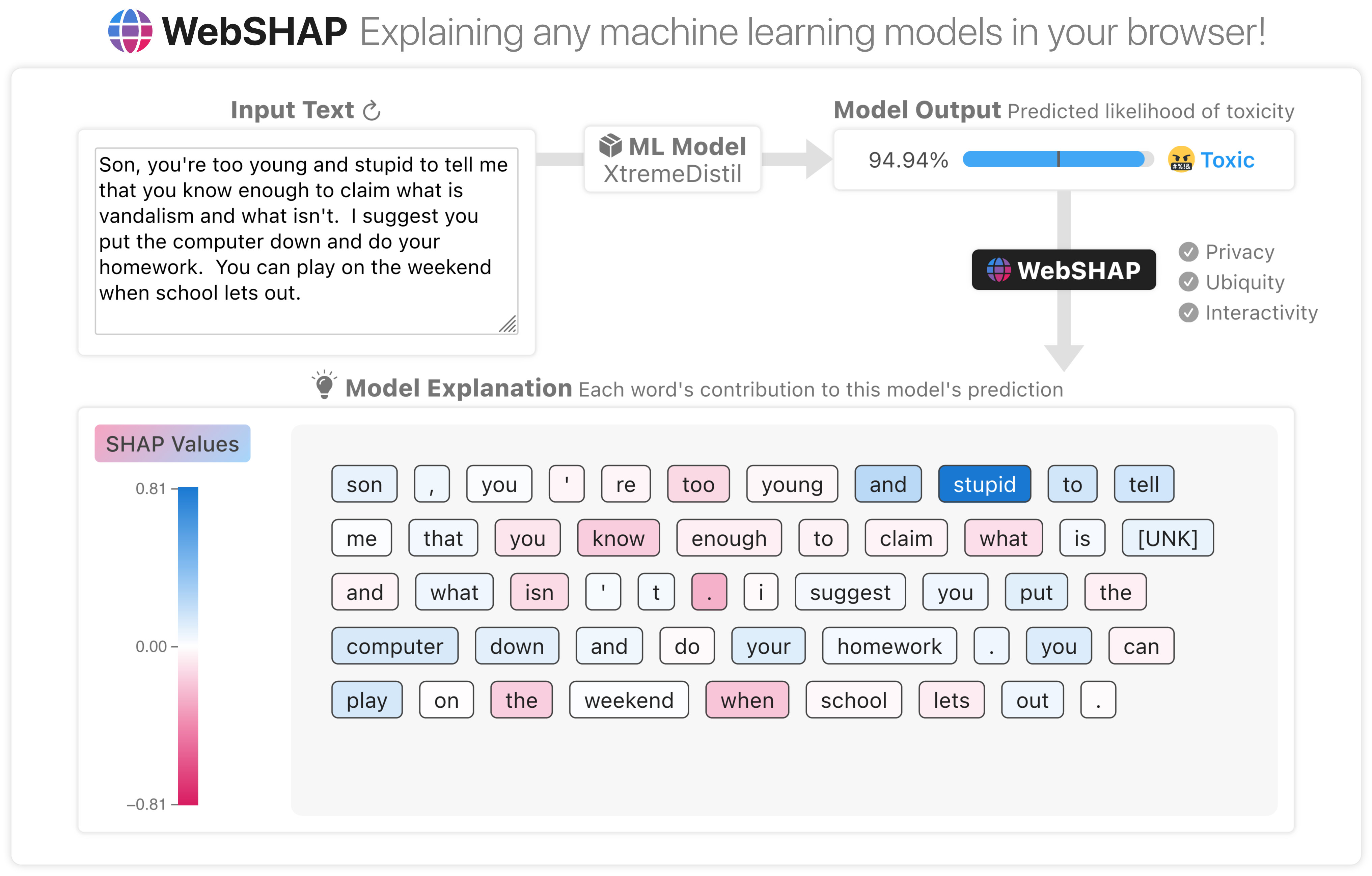
WebSHAP

Live Demo List (see Repository README.md for more info)
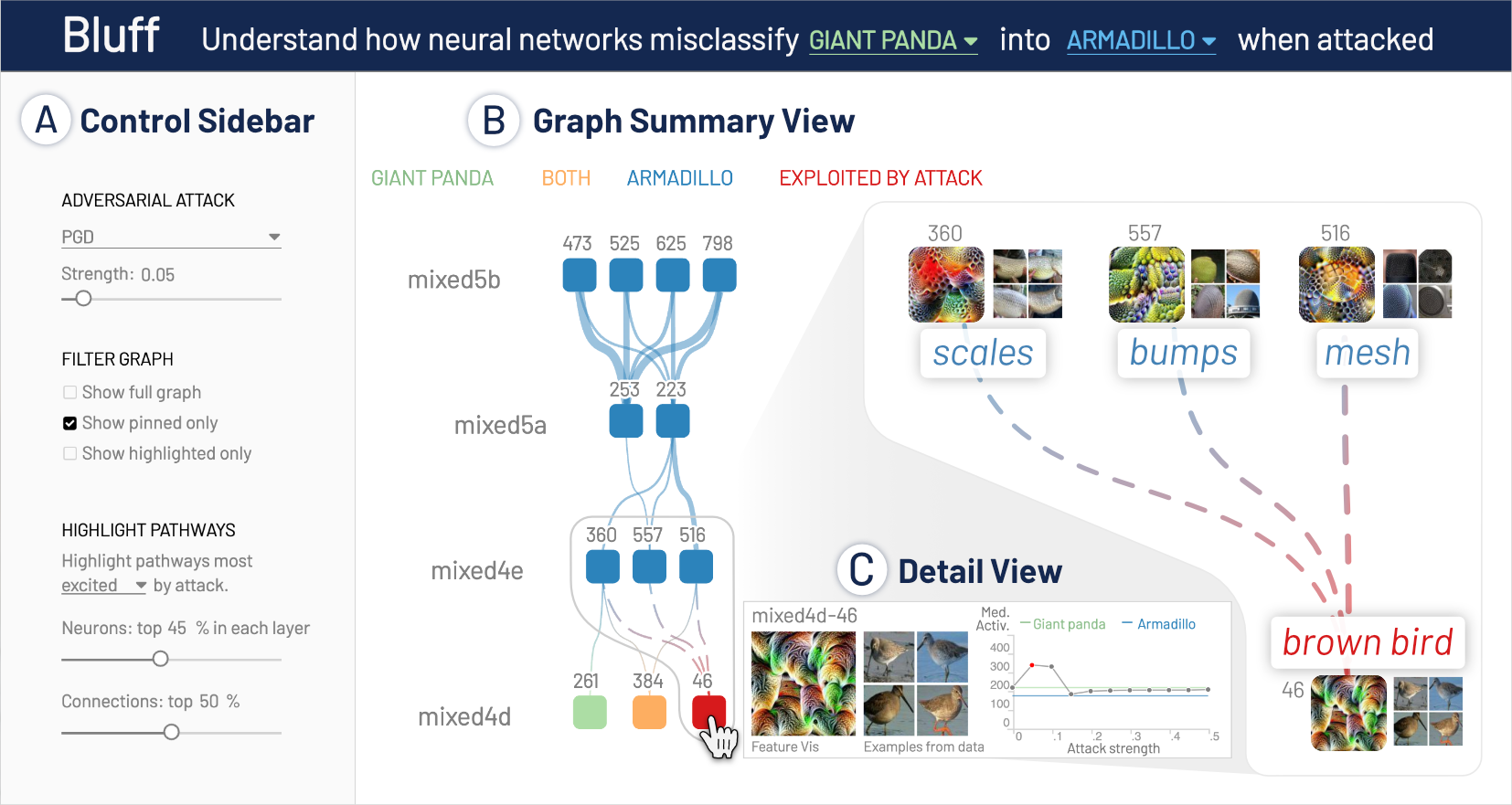
Bluff
Dodrio
An interactive visualization system designed to help NLP researchers and practitioners analyze and compare attention weights in transformer-based models with linguistic knowledge.

Neuro-Cartography
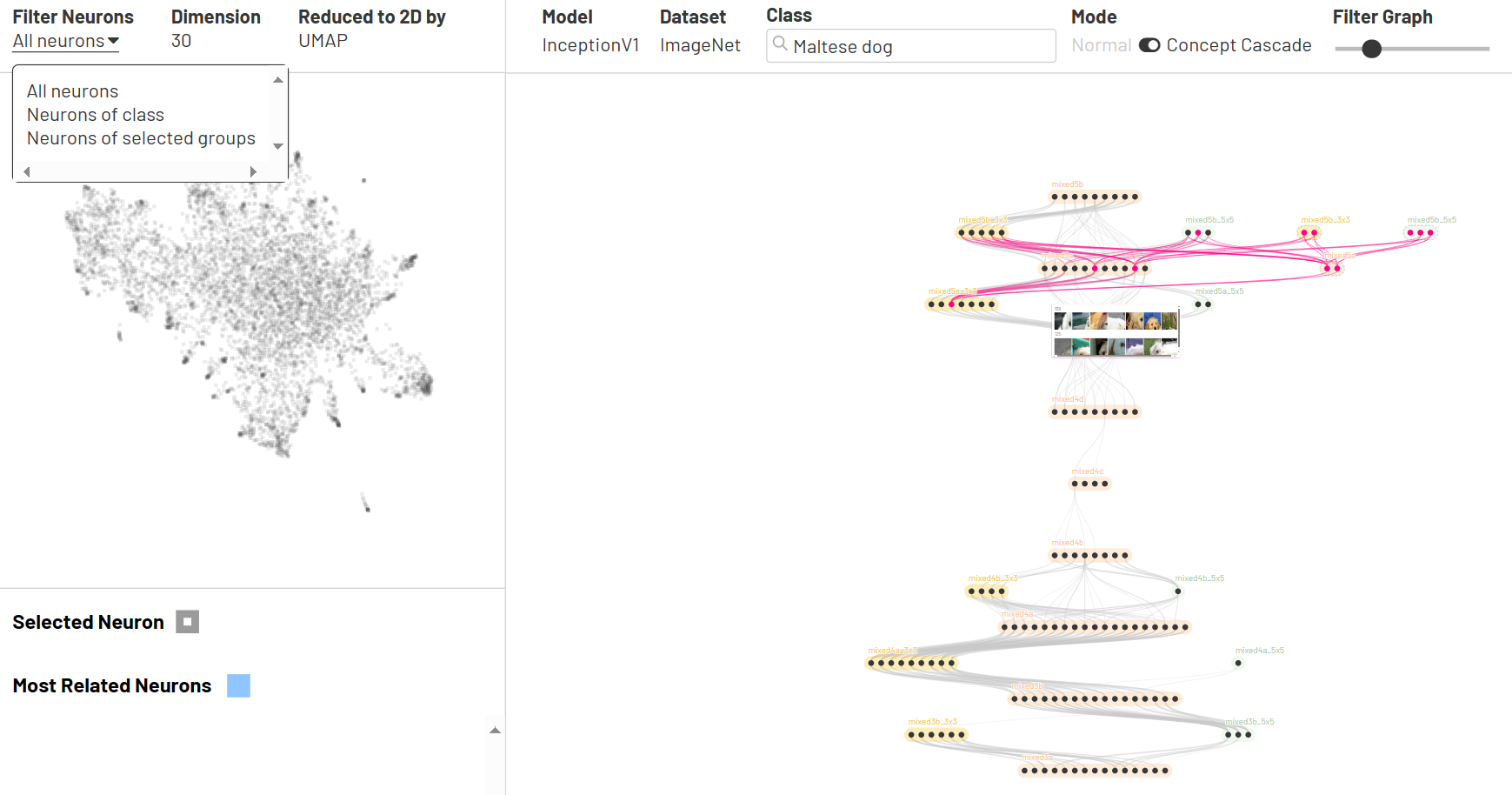
Visual Auditor
An interactive visualization system for identifying and understanding biases in machine learning models.
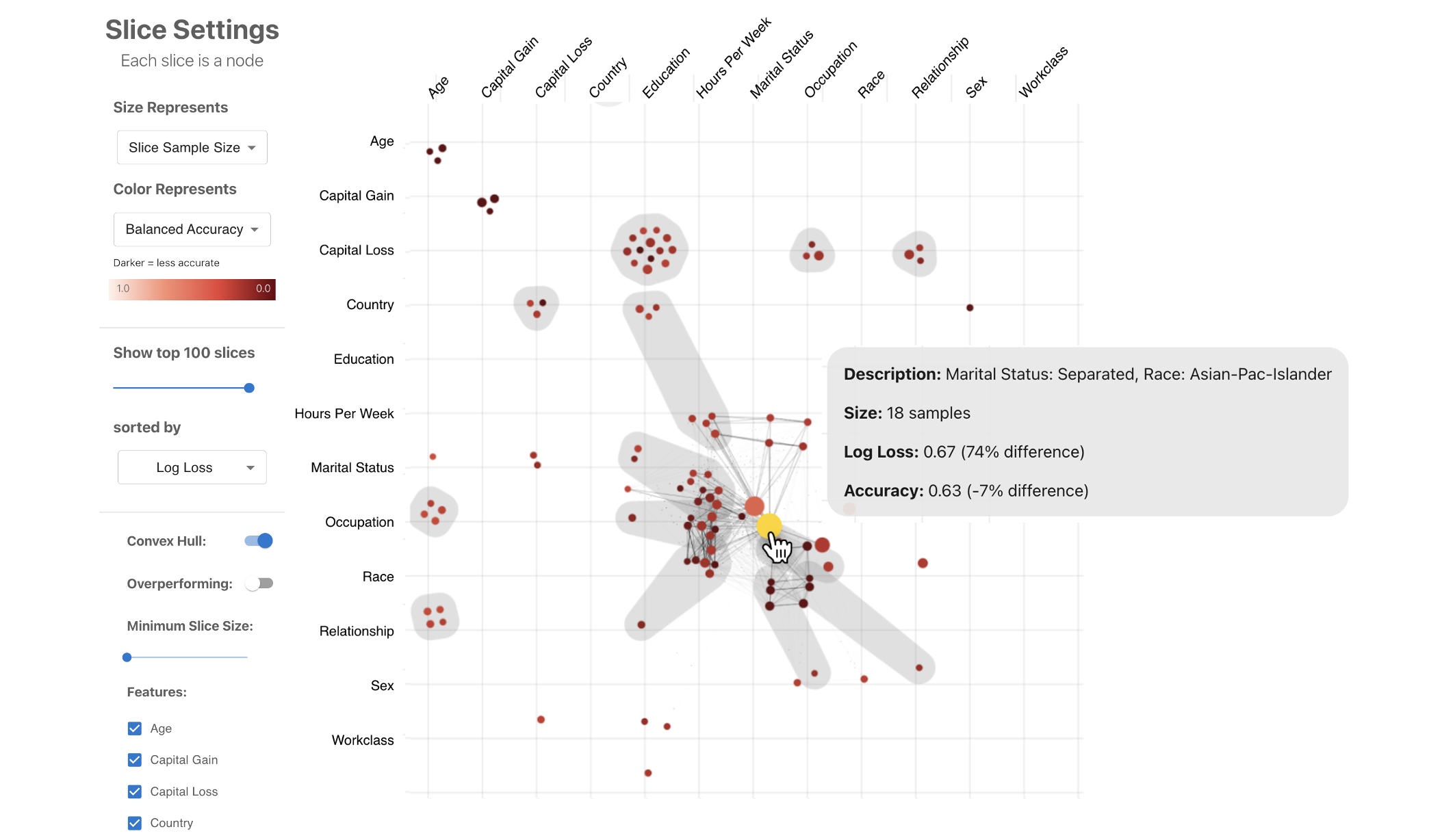
TeleGam
TeleGam is a prototype system that demonstrates how visualizations and verbalizations can collectively support interactive interpretation of machine learning models, for example, generalized additive models (GAMs).

Convolution Sandbox
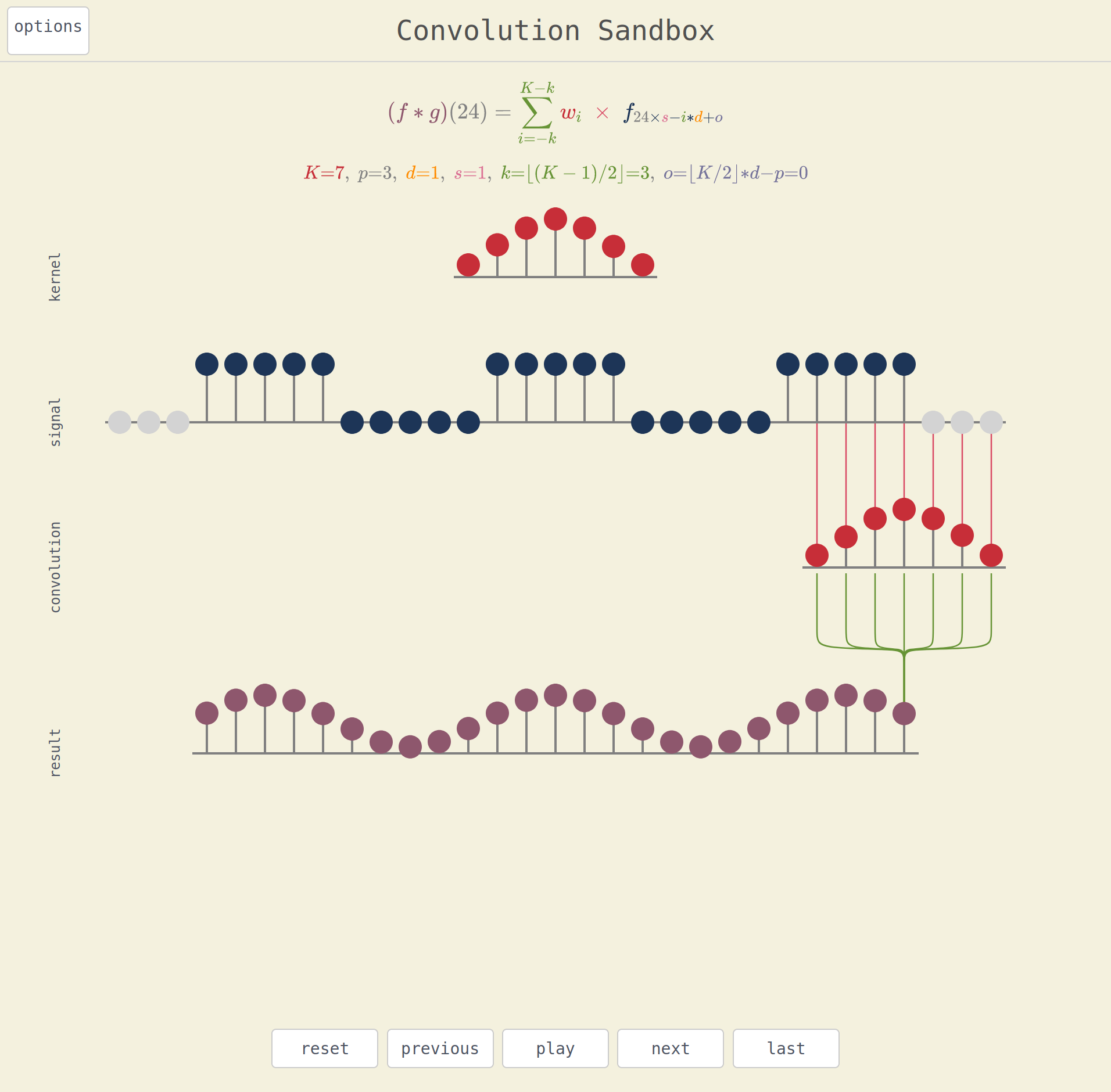
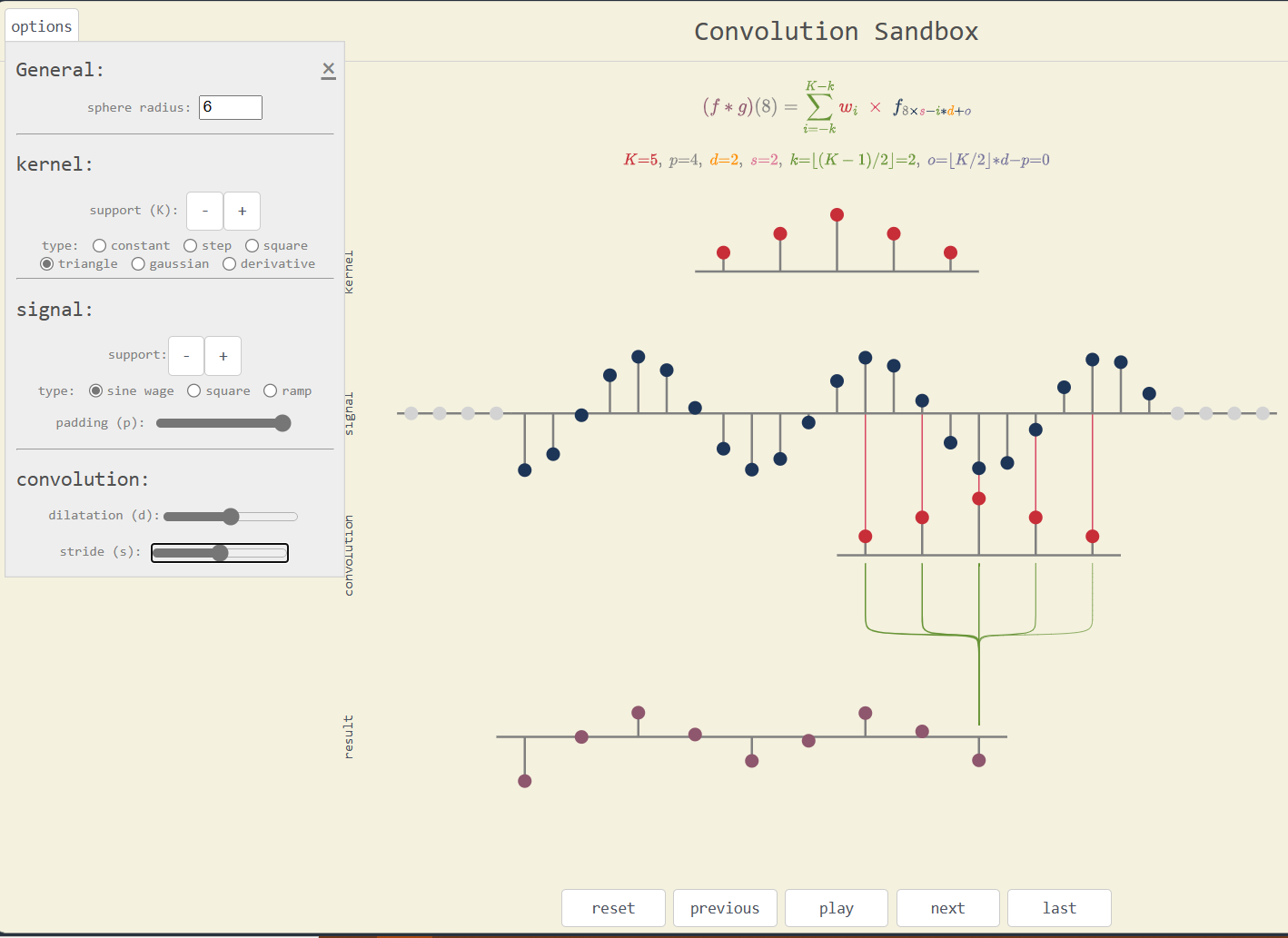
Convolutions are core to deep learning recent success, especially in computer vision. This interactive visualization help to grasp a better understanding of the step-by-step processing.
User can select different kernels and input signals among the predefined functions. Another option drag the dots to the wanted level. The app also illustrates the importance of the padding, the dilatation and stride parameters.
Additional Resource Collections
Machine Learning Tokyo’s Interactive Tools
A small sampling of the contents:
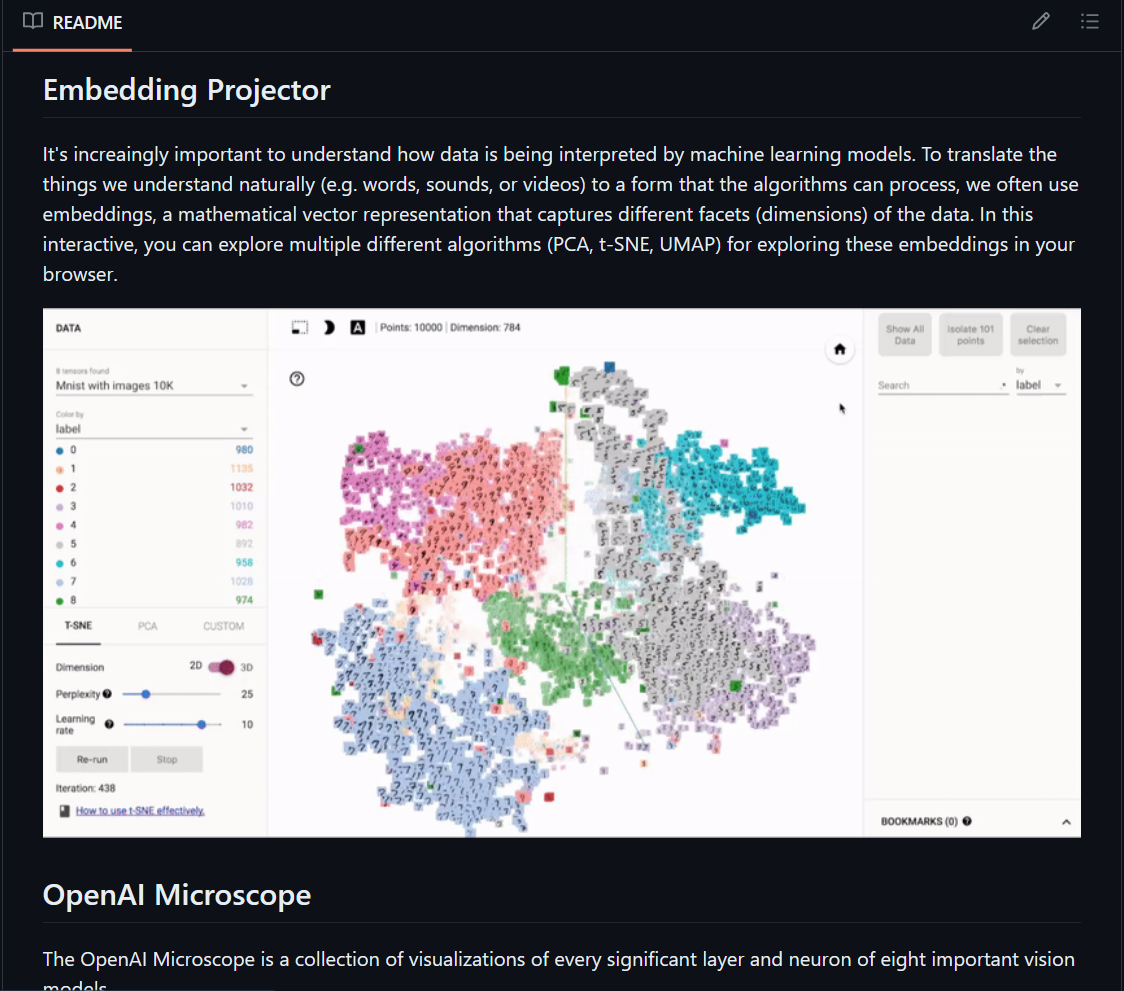
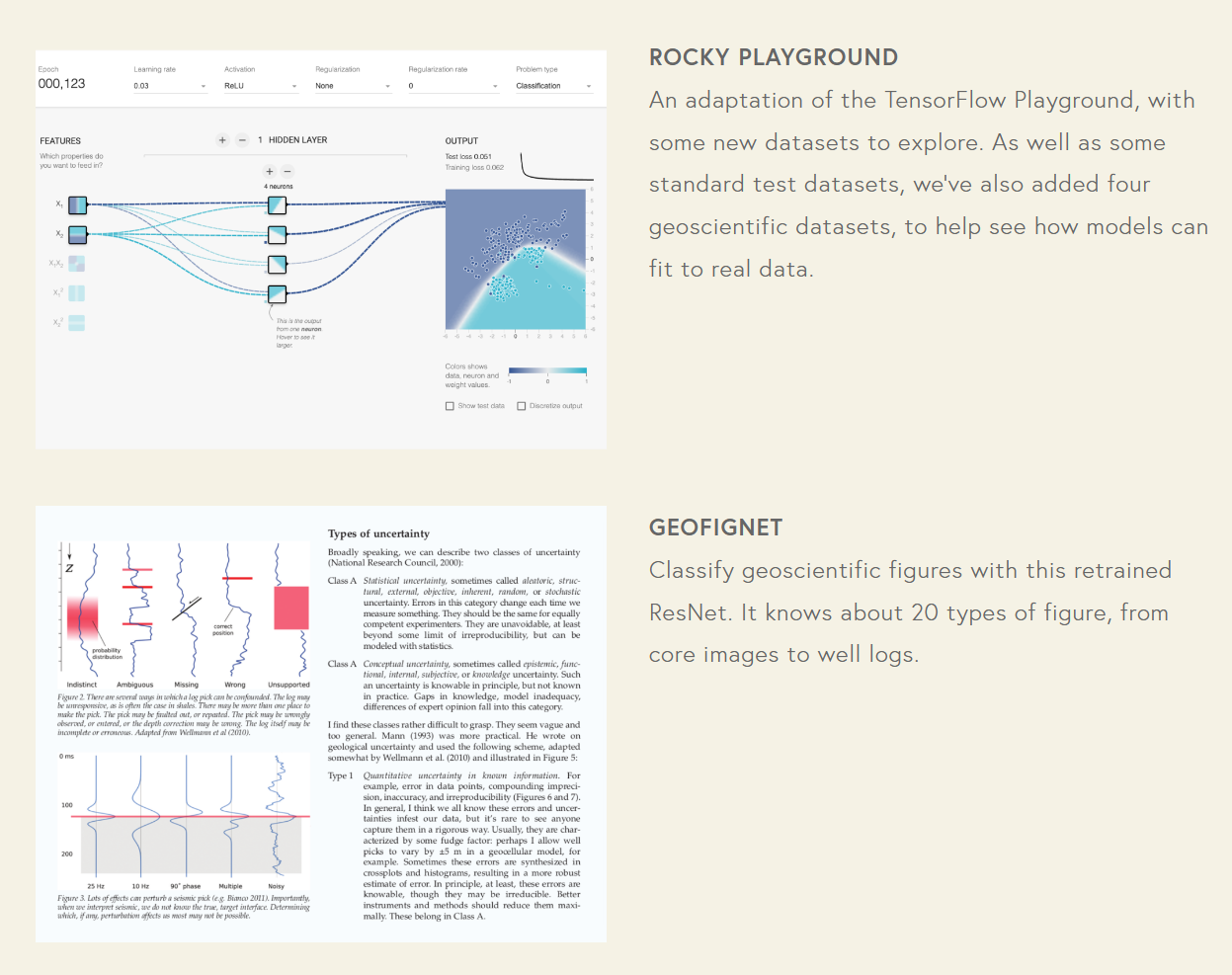
geosci.ai
Contains 9 interactive applications and utilities involving geoscience. About half of them are specifically AI-related as well.

Other Interactive Resource Collections
Topic-Specific Resources
Classification and Regression
Deep Learning and NN Architecture
Transformers
ashishpatel26’s Treasure of Transformers


Specific ML Frameworks
PyTorch
PyTorch 101 Tutorial Series
The repository link contains interactive notebooks corresponding to each blog post in the series.
Series Contents:
- Understanding Graphs, Automatic Differentiation and Autograd
- Building Your First Neural Network
- Going Deep with PyTorch
- Memory Management and Using Multiple GPUs
- Understanding Hooks
bharathgs’ Awesome PyTorch List
TensorFlow (+Keras)
Hands-On Machine Learning…

Course Material
MIT Deep Learning
Contains links to lecture videos and several Jupyter notebooks and Google Colab notebooks for various task-oriented tutorials.
ML Frameworks
C/C++ Frameworks
DeepC
Repository README.md contains links to colab notebook and other reference material.
The deepC is a vendor independent deep learning library, compiler and inference framework designed for small form-factor devices including μControllers, IoT and Edge devices.

Python Frameworks
OpenPrompt

See also UltraChat.
Julia Frameworks
Flux

Flux is a 100% pure-Julia stack and provides lightweight abstractions on top of Julia’s native GPU and AD support. It makes the easy things easy while remaining fully hackable.

MLJ
MLJ (Machine Learning in Julia) is a toolbox written in Julia providing a common interface and meta-algorithms for selecting, tuning, evaluating, composing and comparing about 200 machine learning models written in Julia and other languages.
Focus is mainly not on Deep Learning techniques.
Other Languages
Framework Interop
Reinforcement Learning initiatives
DeepRTS
DeepRTS is a high-performance Real-TIme strategy game for Reinforcement Learning research. It is written in C++ for performance, but provides an python interface to better interface with machine-learning toolkits. Deep RTS can process the game with over 6 000 000 steps per second and 2 000 000 steps when rendering graphics. In comparison to other solutions, such as StarCraft, this is over 15 000% faster simulation time running on Intel i7-8700k with Nvidia RTX 2080 TI.
The aim of Deep RTS is to bring a more affordable and sustainable solution to RTS AI research by reducing computation time.
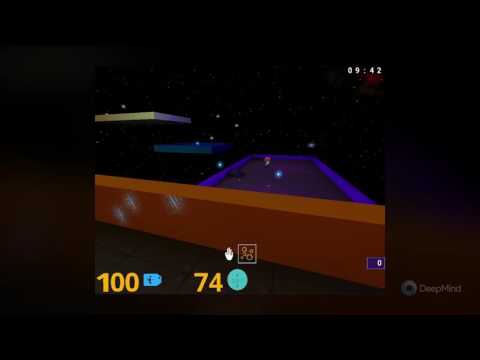
Google Deepmind’s lab

DeepMind Lab is a 3D learning environment based on id Software’s Quake III Arena via ioquake3 and other open source software.
DeepMind Lab provides a suite of challenging 3D navigation and puzzle-solving tasks for learning agents. Its primary purpose is to act as a testbed for research in artificial intelligence, especially deep reinforcement learning.
(Click the images below to watch each of the three demo videos on YouTube.)
Gymnasium

Successor to OpenAI’s Gym (website, repository).
Gymnasium includes the following families of environments along with a wide variety of third-party environments
Classic Control - These are classic reinforcement learning based on real-world problems and physics.
Box2D - These environments all involve toy games based around physics control, using box2d based physics and PyGame-based rendering
Toy Text - These environments are designed to be extremely simple, with small discrete state and action spaces, and hence easy to learn. As a result, they are suitable for debugging implementations of reinforcement learning algorithms.
MuJoCo - A physics engine based environments with multi-joint control which are more complex than the Box2D environments.
Atari - A set of 57 Atari 2600 environments simulated through Stella and the Arcade Learning Environment that have a high range of complexity for agents to learn.
Third-party - A number of environments have been created that are compatible with the Gymnasium API. Be aware of the version that the software was created for and use the apply_env_compatibility in gymnasium.make if necessary.
ML Libraries
AutoML
Python
Optuna

Optuna is an automatic hyperparameter optimization software framework, particularly designed for machine learning. It features an imperative, define-by-run style user API. Thanks to our define-by-run API, the code written with Optuna enjoys high modularity, and the user of Optuna can dynamically construct the search spaces for the hyperparameters.
Optuna has modern functionalities as follows:
Lightweight, versatile, and platform agnostic architecture
Handle a wide variety of tasks with a simple installation that has few requirements.
Pythonic search spaces
*Define search spaces using familiar Python syntax including conditionals and loops.*
Efficient optimization algorithms
Adopt state-of-the-art algorithms for sampling hyperparameters and efficiently pruning unpromising trials.
Easy parallelization
Scale studies to tens or hundreds of workers with little or no changes to the code.
Quick visualization
Inspect optimization histories from a variety of plotting functions.
Optuna is popular and is generally regarded as accessible to beginners.
Hyperopt

Hyperopt is a Python library for serial and parallel optimization over awkward search spaces, which may include real-valued, discrete, and conditional dimensions.
Currently three algorithms are implemented in hyperopt:
- Random Search
- Tree of Parzen Estimators (TPE)
- Adaptive TPE
Hyperopt has been designed to accommodate Bayesian optimization algorithms based on Gaussian processes and regression trees, but these are not currently implemented.
All algorithms can be parallelized in two ways, using:
- Apache Spark
- MongoDB
HyperOpt is also extremely popular.
NNI

NNI automates feature engineering, neural architecture search, hyperparameter tuning, and model compression for deep learning. Find the latest features, API, examples and tutorials in our official documentation.
The documentation has several tutorials and quick-start guides for a variety of situations, but its coverage for nonstandard operations is less than thorough (and in some places is outdated and/or self-contradictory).
Auto-PyTorch
While early AutoML frameworks focused on optimizing traditional ML pipelines and their hyperparameters, another trend in AutoML is to focus on neural architecture search. To bring the best of these two worlds together, we developed Auto-PyTorch, which jointly and robustly optimizes the network architecture and the training hyperparameters to enable fully automated deep learning (AutoDL).
Auto-PyTorch is mainly developed to support tabular data (classification, regression) and time series data (forecasting). The newest features in Auto-PyTorch for tabular data are described in the paper “Auto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL” (see below for bibtex ref). Details about Auto-PyTorch for multi-horizontal time series forecasting tasks can be found in the paper “Efficient Automated Deep Learning for Time Series Forecasting”.
FLAML

FLAML is a lightweight Python library for efficient automation of machine learning and AI operations. It automates workflow based on large language models, machine learning models, etc. and optimizes their performance.
FLAML enables building next-gen GPT-X applications based on multi-agent conversations with minimal effort. It simplifies the orchestration, automation and optimization of a complex GPT-X workflow. It maximizes the performance of GPT-X models and augments their weakness.
For common machine learning tasks like classification and regression, it quickly finds quality models for user-provided data with low computational resources. It is easy to customize or extend. Users can find their desired customizability from a smooth range.
It supports fast and economical automatic tuning (e.g., inference hyperparameters for foundation models, configurations in MLOps/LMOps workflows, pipelines, mathematical/statistical models, algorithms, computing experiments, software configurations), capable of handling large search space with heterogeneous evaluation cost and complex constraints/guidance/early stopping.
Featuretools

Featuretools automatically creates features from temporal and relational datasets.

DeepHyper

DeepHyper is a powerful Python package for automating machine learning tasks, particularly focused on optimizing hyperparameters, searching for optimal neural architectures, and quantifying uncertainty through the deep ensembles. With DeepHyper, users can easily perform these tasks on a single machine or distributed across multiple machines, making it ideal for use in a variety of environments. Whether you’re a beginner looking to optimize your machine learning models or an experienced data scientist looking to streamline your workflow, DeepHyper has something to offer. So why wait? Start using DeepHyper today and take your machine learning skills to the next level!
AutoGluon

See the website for several Quick Start guides and tutorials.
AdaNet

AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention. AdaNet builds on recent AutoML efforts to be fast and flexible while providing learning guarantees. Importantly, AdaNet provides a general framework for not only learning a neural network architecture, but also for learning to ensemble to obtain even better models.
Neuraxio

The world’s cleanest AutoML library ✨ - Do hyperparameter tuning with the right pipeline abstractions to write clean deep learning production pipelines. Let your pipeline steps have hyperparameter spaces. Design steps in your pipeline like components. Compatible with Scikit-Learn, TensorFlow, and most other libraries, frameworks and MLOps environments.
Time series
Python
Temporian

Temporian is a library for safe, simple and efficient preprocessing and feature engineering of temporal data in Python. Temporian supports multivariate time-series, multivariate time-sequences, event logs, and cross-source event streams.
functime

functime is a machine learning library for time-series predictions that just works.
- Fully-featured: Powerful and easy-to-use API for forecasting and feature engineering (tsfresh, Catch22).
- Fast: Forecast 100,000 time series in seconds on your laptop
- Efficient: Extract 100s of time-series features in parallel using Polars
- Battle-tested: Algorithms that deliver real business impact and win competitions
tsflex
tsflex … [is] a sequence first Python toolkit for processing & feature extraction, making few assumptions about input data. This makes tsflex suitable for use-cases such as inference on streaming data, performing operations on irregularly sampled series, a holistic approach for operating on multivariate asynchronous data, and dealing with time-gaps.
GluonTS
PyTorch-Forecasting
Explainable DL
Python
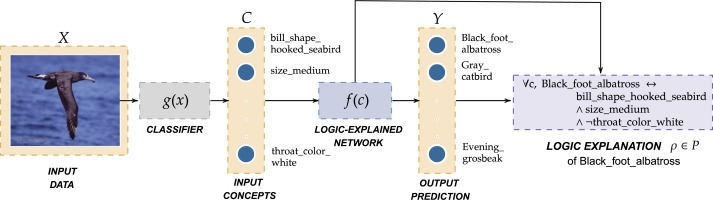
Logic Explained Networks
The Logic Explained Network is a python repository providing a set of utilities and modules to build deep learning models that are explainable by design. This library provides both already implemented LENs classes and APIs classes to get First-Order Logic (FOL) explanations from neural networks.

Streaming ML
River
See also deep-river at https://github.com/online-ml/deep-river: “deep-river is a Python library for online deep learning. deep-river’s ambition is to enable online machine learning for neural networks. It combines the river API with the capabilities of designing neural networks based on PyTorch.”
Plotting and Data Visualization
Python
seaborn
Perspective
Perspective is an interactive analytics and data visualization component, which is especially well-suited for large and/or streaming datasets. Use it to create user-configurable reports, dashboards, notebooks and applications, then deploy stand-alone in the browser, or in concert with Python and/or Jupyterlab.
scikit-learn alternatives
PyCaret
Architecture-Specific
Transformers
Python
HuggingFace transformers
See also this list of “Awesome projects built with transformers.”
NLP
Python
spaCy
spaCy is a library for advanced Natural Language Processing in Python and Cython. It’s built on the very latest research, and was designed from day one to be used in real products.
spaCy comes with pretrained pipelines and currently supports tokenization and training for 70+ languages. It features state-of-the-art speed and neural network models for tagging, parsing, named entity recognition, text classification and more, multi-task learning with pretrained transformers like BERT, as well as a production-ready training system and easy model packaging, deployment and workflow management. spaCy is commercial open-source software, released under the MIT license.
Appears to use PyTorch for GPU support.
FARM (Framework for Adapting Representation Models)

Contextualized Topic Models

Contextualized Topic Models (CTM) are a family of topic models that use pre-trained representations of language (e.g., BERT) to support topic modeling. See the papers for details:
- Bianchi, F., Terragni, S., & Hovy, D. (2021). Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence. ACL. https://aclanthology.org/2021.acl-short.96/
- Bianchi, F., Terragni, S., Hovy, D., Nozza, D., & Fersini, E. (2021). Cross-lingual Contextualized Topic Models with Zero-shot Learning. EACL. https://www.aclweb.org/anthology/2021.eacl-main.143/
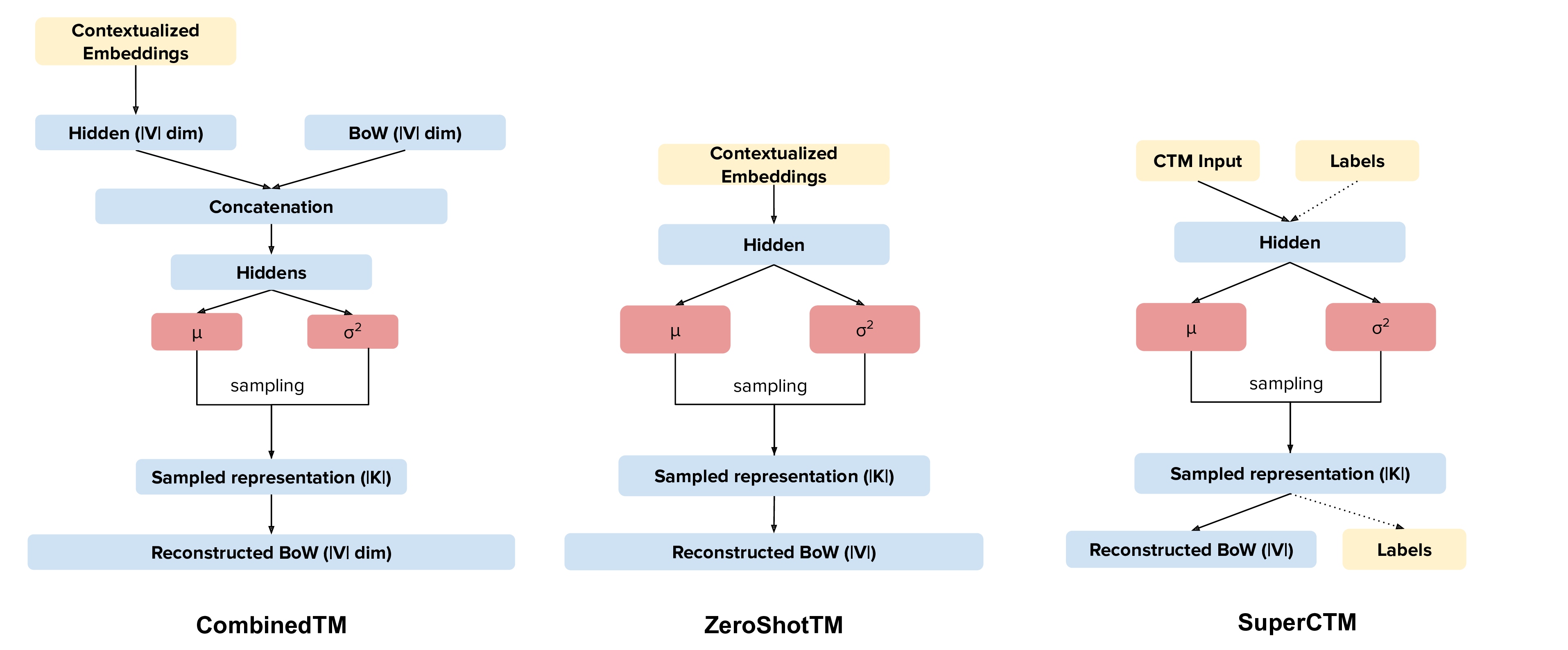
Our new topic modeling family supports many different languages (i.e., the one supported by HuggingFace models) and comes in two versions: CombinedTM combines contextual embeddings with the good old bag of words to make more coherent topics; ZeroShotTM is the perfect topic model for task in which you might have missing words in the test data and also, if trained with multilingual embeddings, inherits the property of being a multilingual topic model!
The big advantage is that you can use different embeddings for CTMs. Thus, when a new embedding method comes out you can use it in the code and improve your results. We are not limited by the BoW anymore.
An important aspect to take into account is which network you want to use: the one that combines contextualized embeddings and the BoW (CombinedTM) or the one that just uses contextualized embeddings (ZeroShotTM).
But remember that you can do zero-shot cross-lingual topic modeling only with the ZeroShotTM model.
Contextualized Topic Models also support supervision (SuperCTM).
We also have Kitty: a new submodule you can use to create a human-in-the-loop classifier to quickly classify your documents and create named clusters. This can be very useful to do document filtering. It also works in cross-lingual setting and thus you might be able to filter documents in a language you don’t know!
Repository README.md includes links to four Google Colab tutorial notebooks.
CUDA GPU support via PyTorch.
skweak

Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
skweak (pronounced /skwi:k/) is a Python-based software toolkit that provides a concrete solution to this problem using weak supervision. skweak is built around a very simple idea: Instead of annotating texts by hand, we define a set of labelling functions to automatically label our documents, and then aggregate their results to obtain a labelled version of our corpus.
The labelling functions may take various forms, such as domain-specific heuristics (like pattern-matching rules), gazetteers (based on large dictionaries), machine learning models, or even annotations from crowd-workers. The aggregation is done using a statistical model that automatically estimates the relative accuracy (and confusions) of each labelling function by comparing their predictions with one another.
skweak can be applied to both sequence labelling and text classification, and comes with a complete API that makes it possible to create, apply and aggregate labelling functions with just a few lines of code. The toolkit is also tightly integrated with SpaCy, which makes it easy to incorporate into existing NLP pipelines. Give it a try!
Medical Imaging
Python
MedicalZooPytorch
A 3D multi-modal medical image segmentation library in PyTorch
Includes quick-start guide and Colab tutorial notebook.
Dev Tools
NN Design Software
Cerbrec Graphbook
The diagramming platform that allows data scientists to focus on model architecture
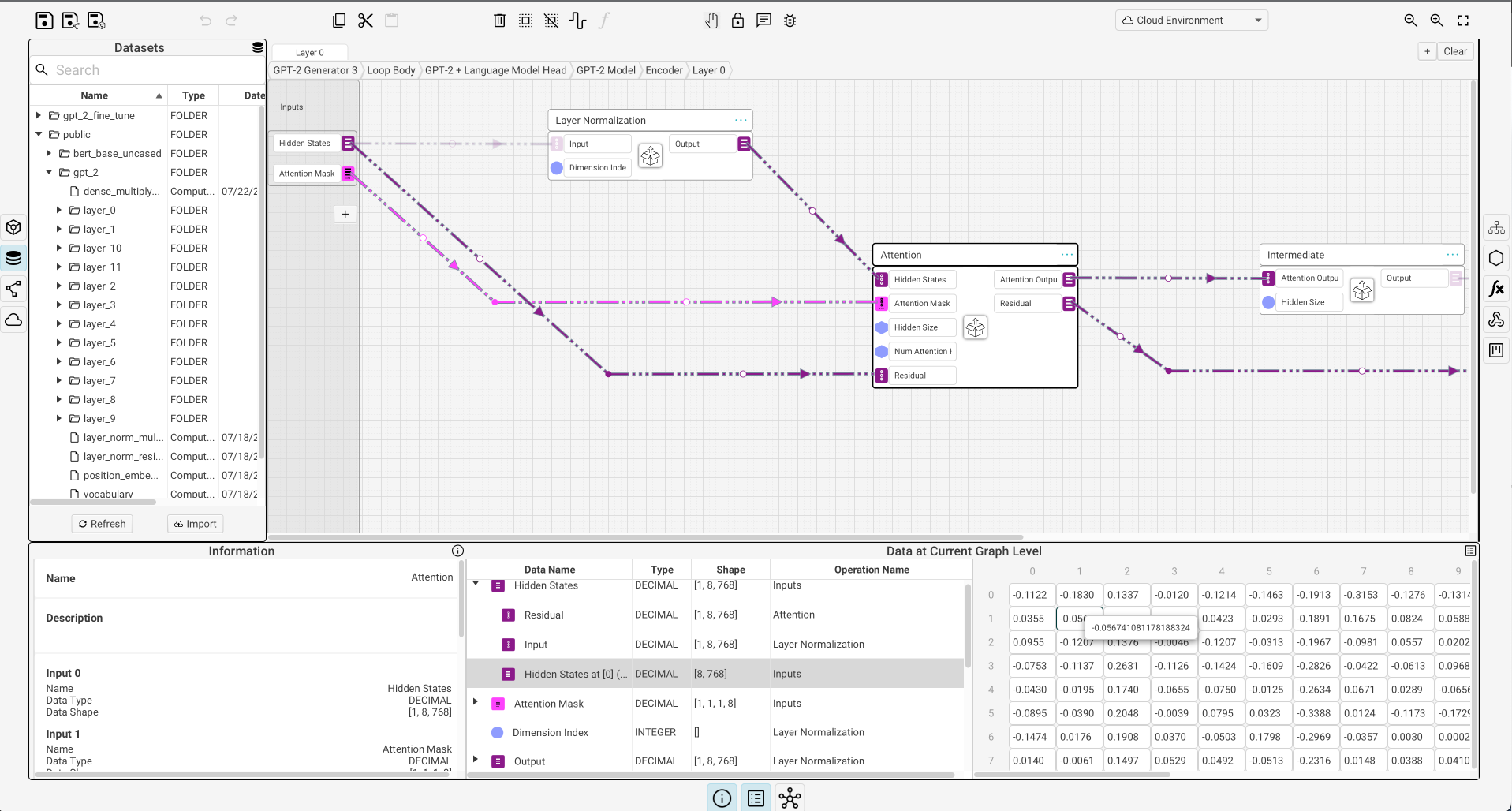
Graphbook is a new visual IDE for AI and deep learning model development that lets you build and run directly on a visualization. For example, you can customize transformers directly in the platform, train, and serve them to a URL. Graphbook is still in beta mode and we are developing more models and product features over time.
The Github repository contains a number of NLP models, grouped into the following categories:
- Classifiers
- Generators
- Next Token
- Tokenizers
- Transformers
There is also a small Community Gallery.
A Python scripting interface (“PyGraphbook”) is in progress.
NN Visualization Tools
nn_vis
Collection of NN Architecture Visualization Tools
NN Architecture “Zoos”
modelzoo.co
Models are grouped by framework (ex. PyTorch, TensorFlow) as well as by category (Computer Vision, NLP, RL, etc).
Reinforcement Learning Misc.
DeepRTS
Misc. Tools
(UNDER CONSTRUCTION)
Data Science Tools
Notebook Tools
Quarto
Diagrams
Markup Languages
D2
svgbob
Svgbob is a diagramming model which uses a set of typing characters to approximate the intended shape. It uses a combination of characters which are readily available on your keyboards.
What can it do?
- Basic shapes
- Quick logo scribbles
- Even unicode box drawing characters are supported
- Circle, quarter arcs, half circles, 3/4 quarter arcs
- Grids
- Graphics Diagram
- CJK characters
- Sequence Diagrams
- Plot diagrams
- Railroad diagrams
- Statistical charts
- Flow charts
- Block diagrams
- Mindmaps
- It can do complex stuff such as circuit diagrams
- Latest addition: Styling of tagged shapes
Diagram Tools
text-to-diagram.com
Kroki
Domain-Specific Tools
DeepBrain (for medical imaging)
Experiment and Data-Collection Tools
labgraph
LabGraph is a Python framework for rapidly prototyping experimental systems for real-time streaming applications. It is particularly well-suited to real-time neuroscience, physiology and psychology experiments.
Appendix A: Annotation and Notekeeping
Collaborative web annotation
There are probably others, but here is what I have found so far.
hypothes.is

Many notekeeping options (see below) have plugins for integration with Hypothesis.

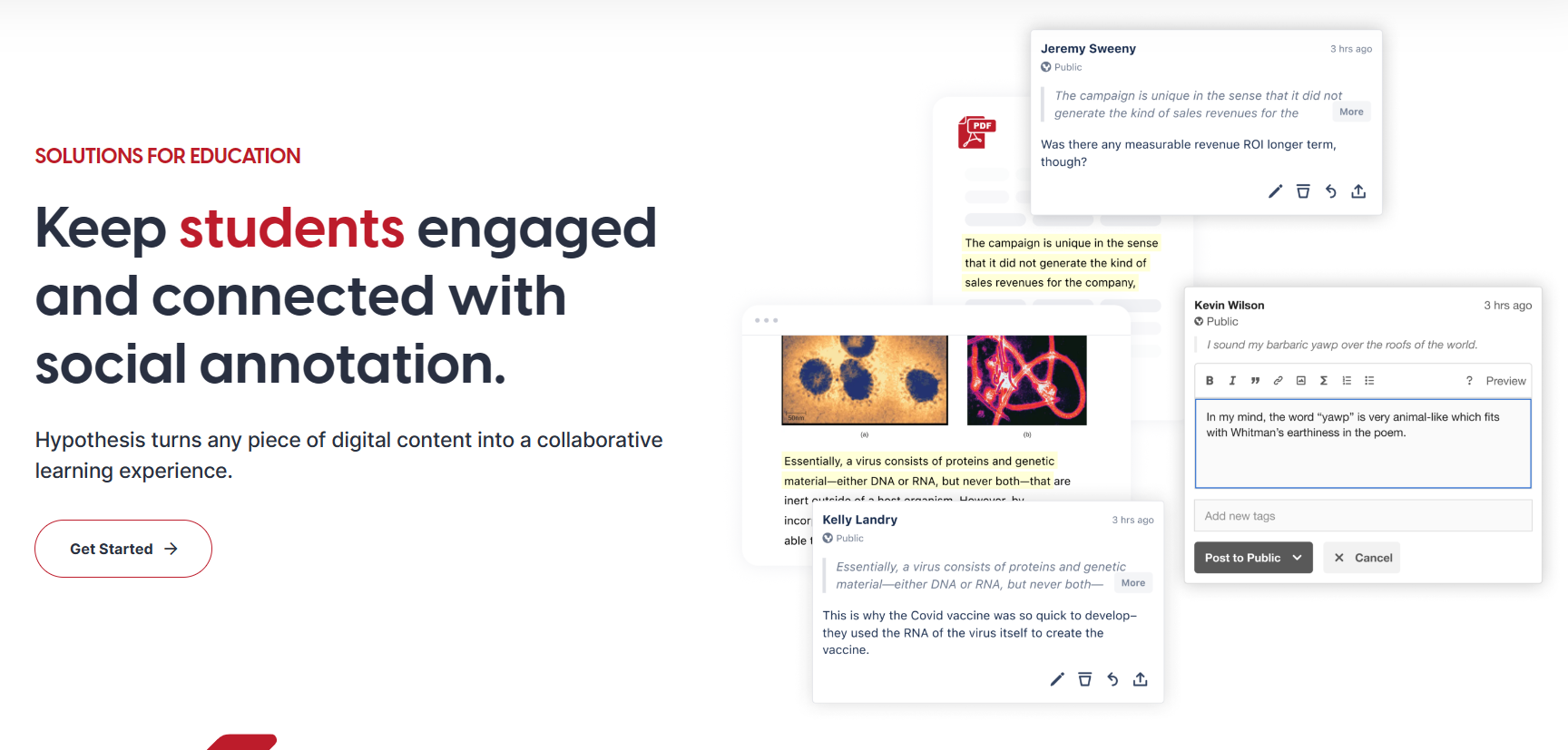
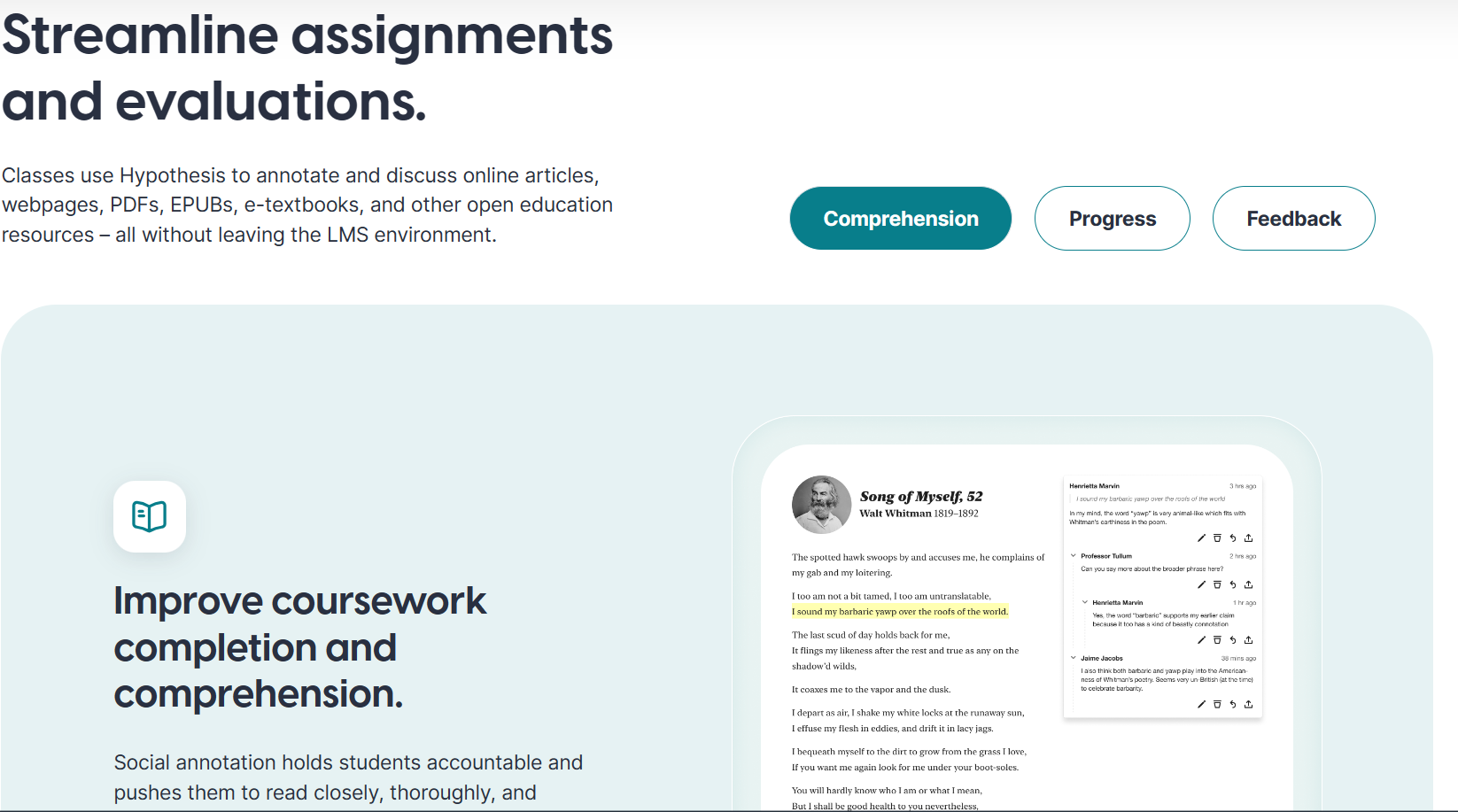
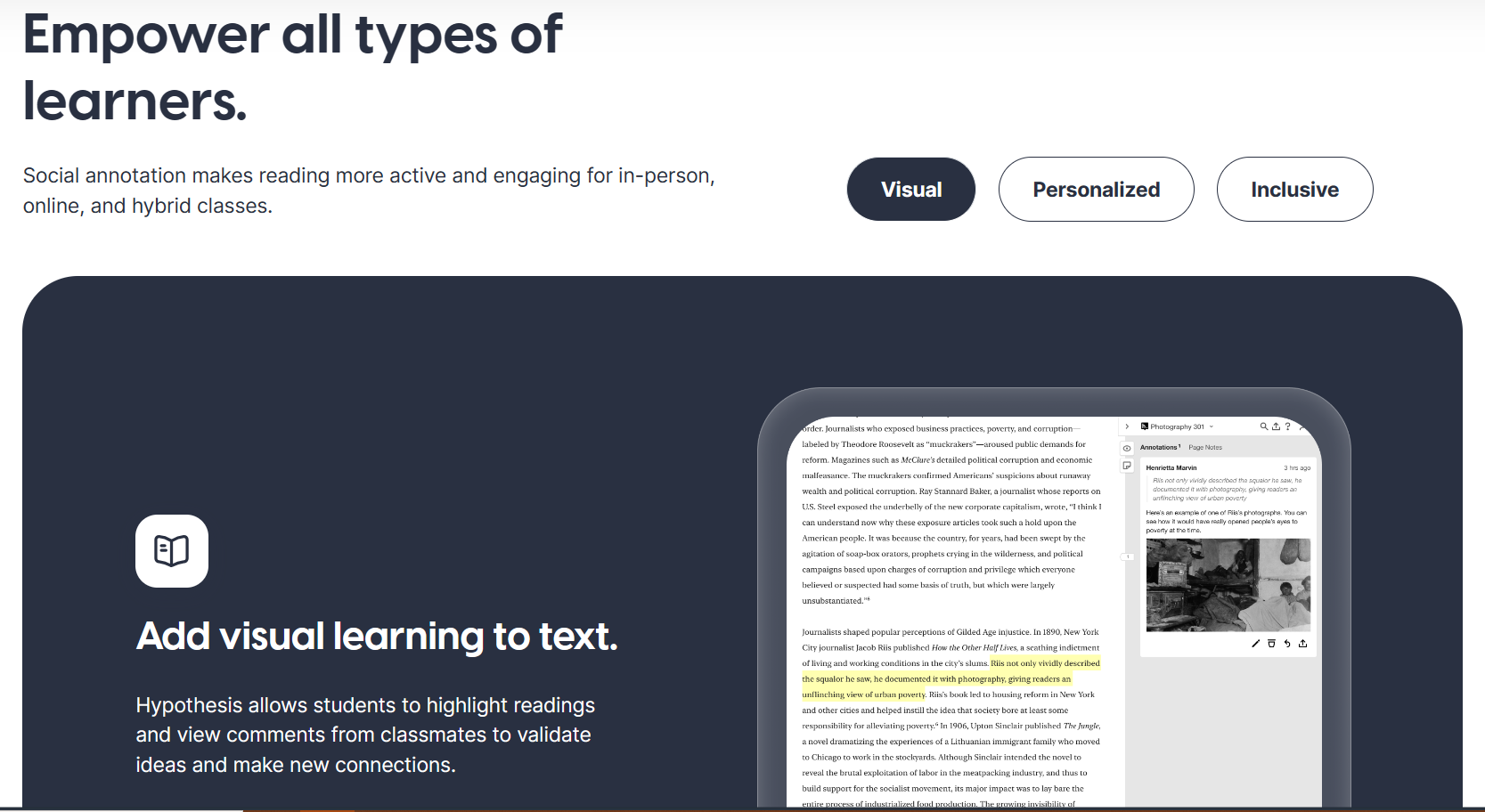
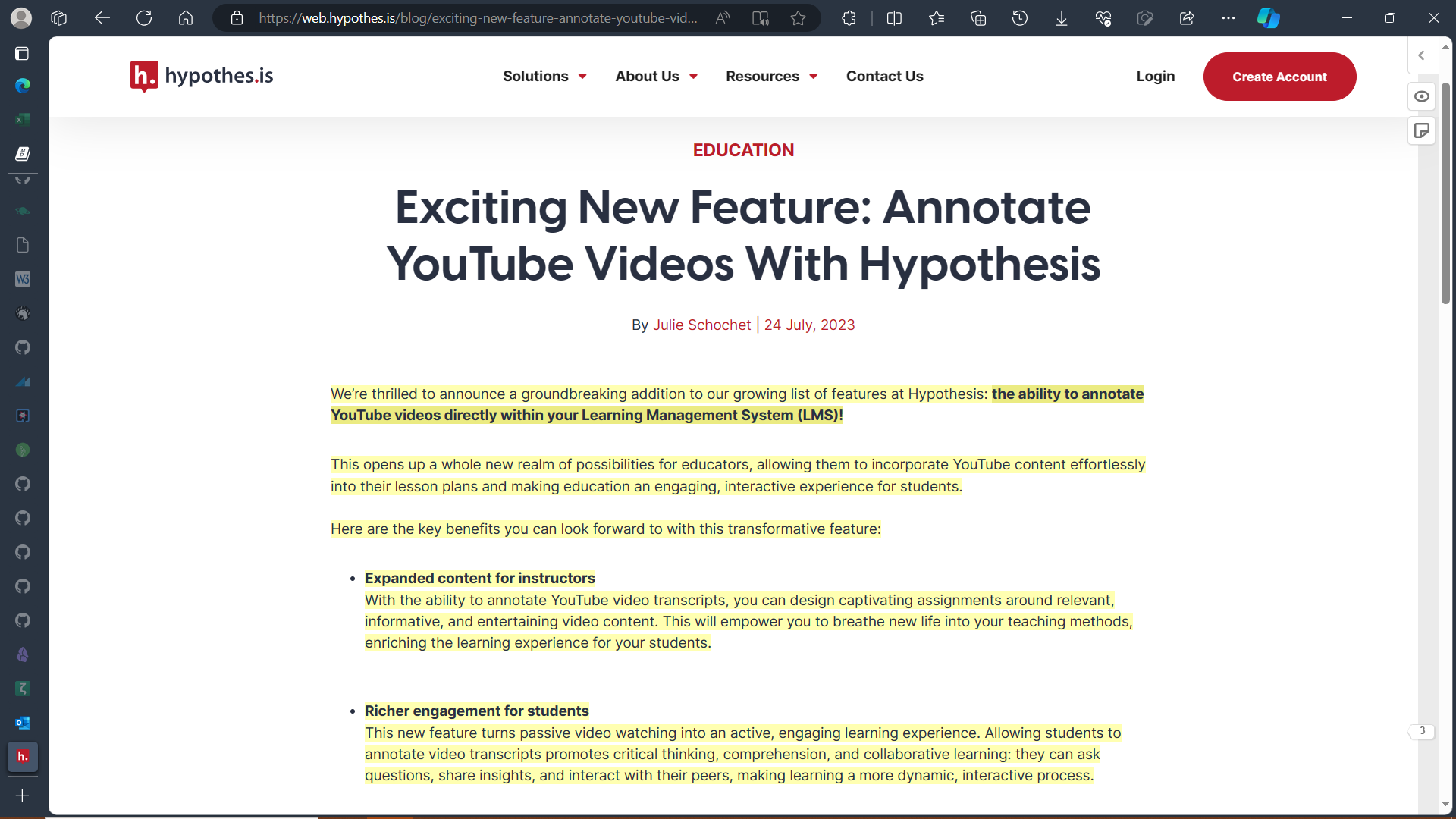
Memex
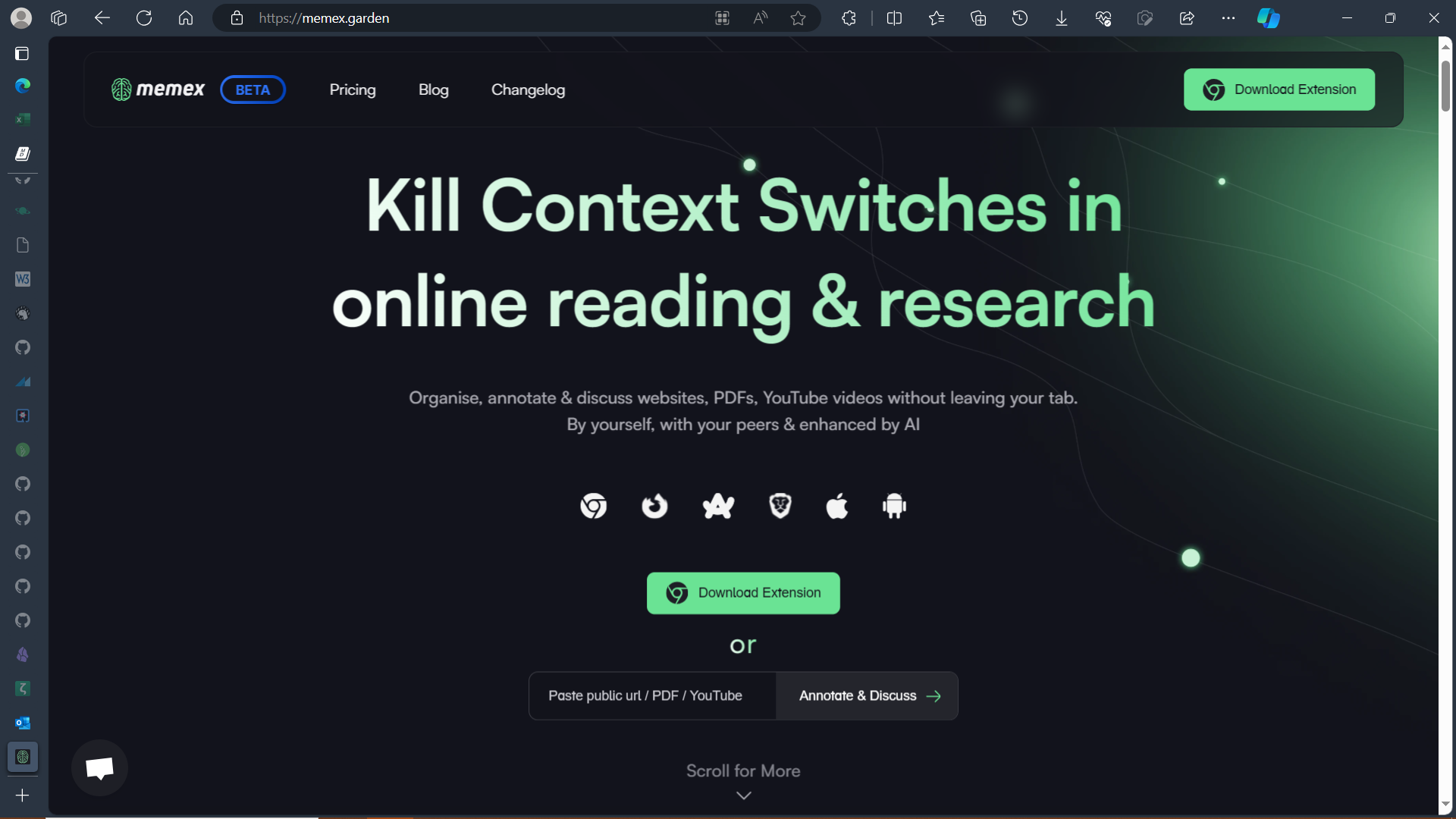
See the website for a demo video for researchers.
Hierarchical note-taking with backlinks and cross-references
Primarily Offline Interface
These offer limited real-time collaboration but don’t have the same lock-in effect (so you aren’t constrained to stay with any particular system, service, or app). Furthermore, unlike the systems that are primarily online services, users can create plugins for them.
Obsidian
Supposedly more well-polished and full-featured than Logseq.
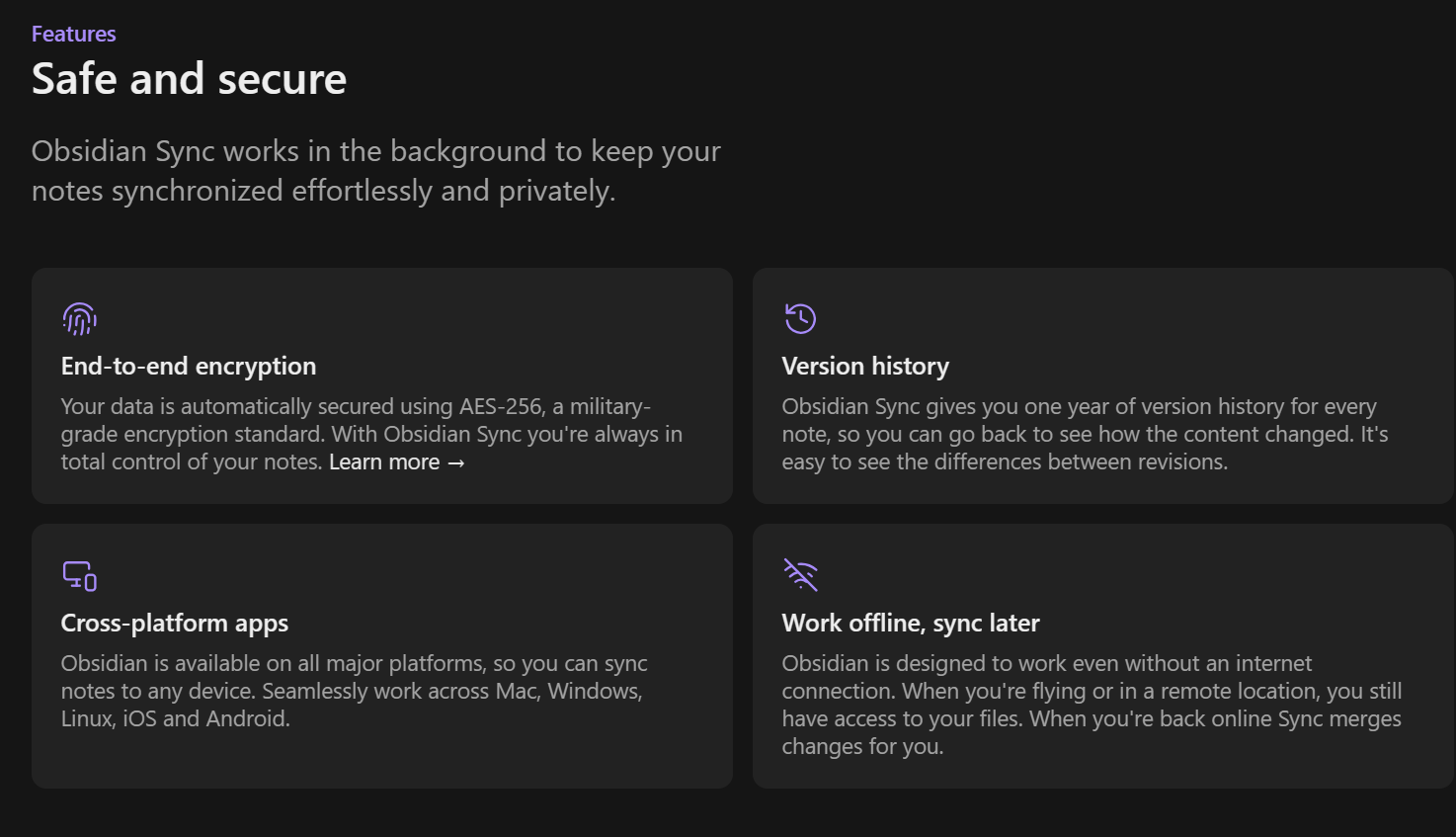
Has plugins (2000+) for Hypothesis integration, time-synced notes on audio files, automatic captioning, PDF annotation, embedded drawings, chemistry diagrams, integrated terminals, graphical chart editing, flashcards and spaced repetition, and more.
Anyone can develop their own plugins with the plugin API.
Has apps for every major platform.
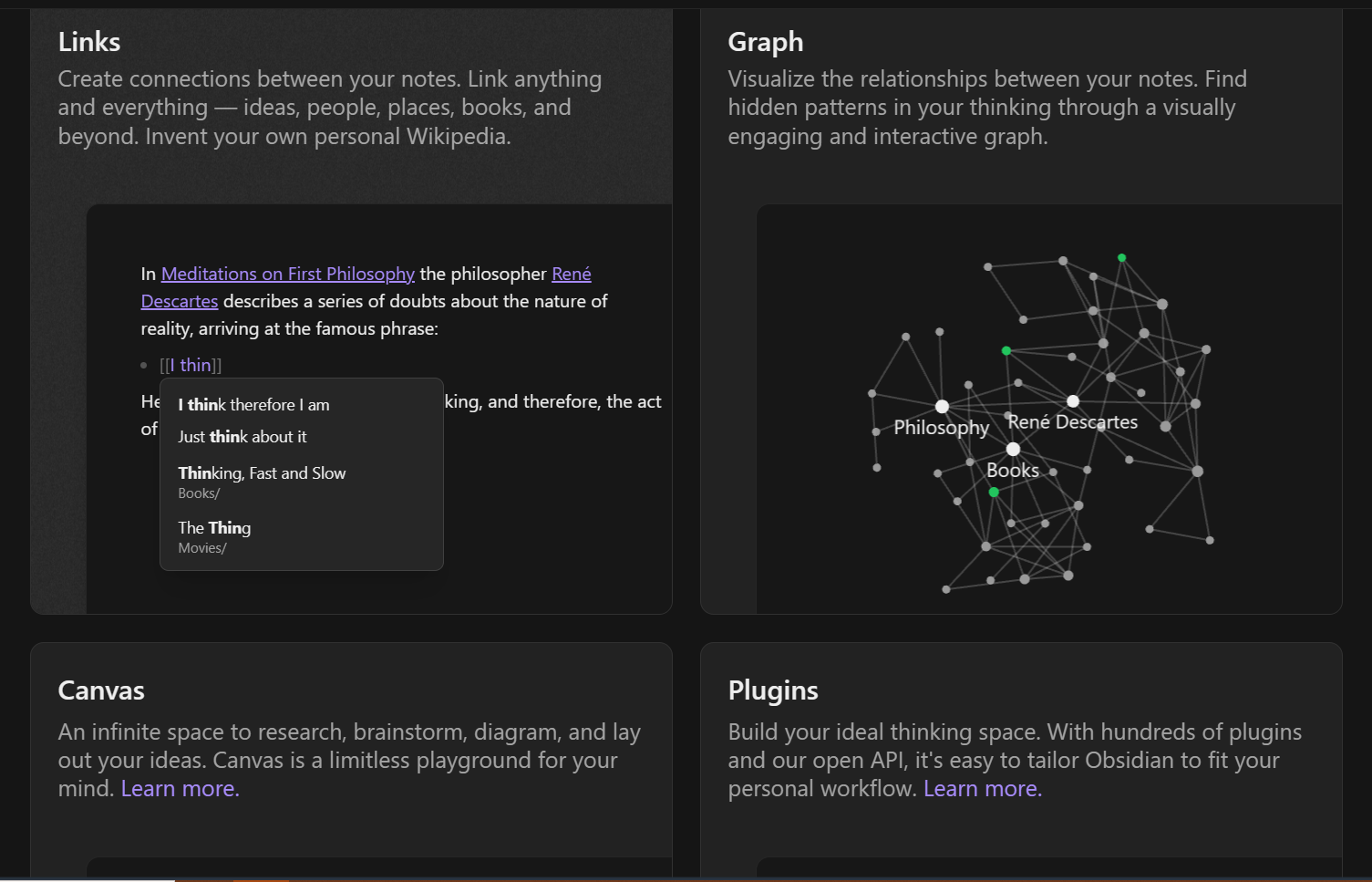
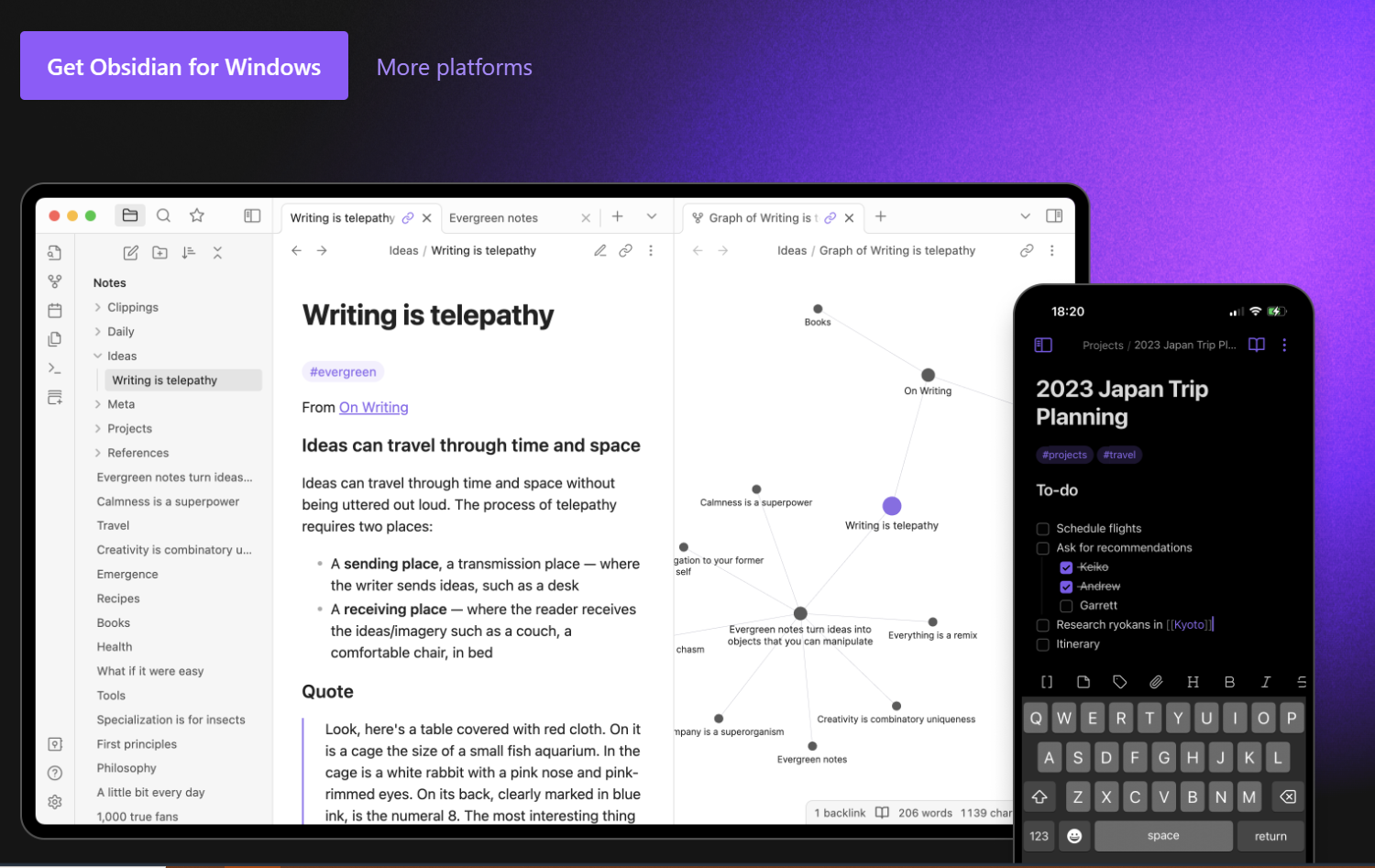
Some additional information
- https://www.eleanorkonik.com/2021-04-24/
- https://www.reddit.com/r/ObsidianMD/comments/v20eb7/vault_showcase_and_tips_and_tricks/
- https://forum.obsidian.md/t/university-setup-with-lecture-notes-progress-bar-and-more-using-templater-dataview-and-buttons/32094
- https://obsidianninja.com/new-obsidian-showcases-dashboards-movie-library-menu-bar-more/
- https://forum.obsidian.md/t/example-workflows-in-obsidian/1093/24
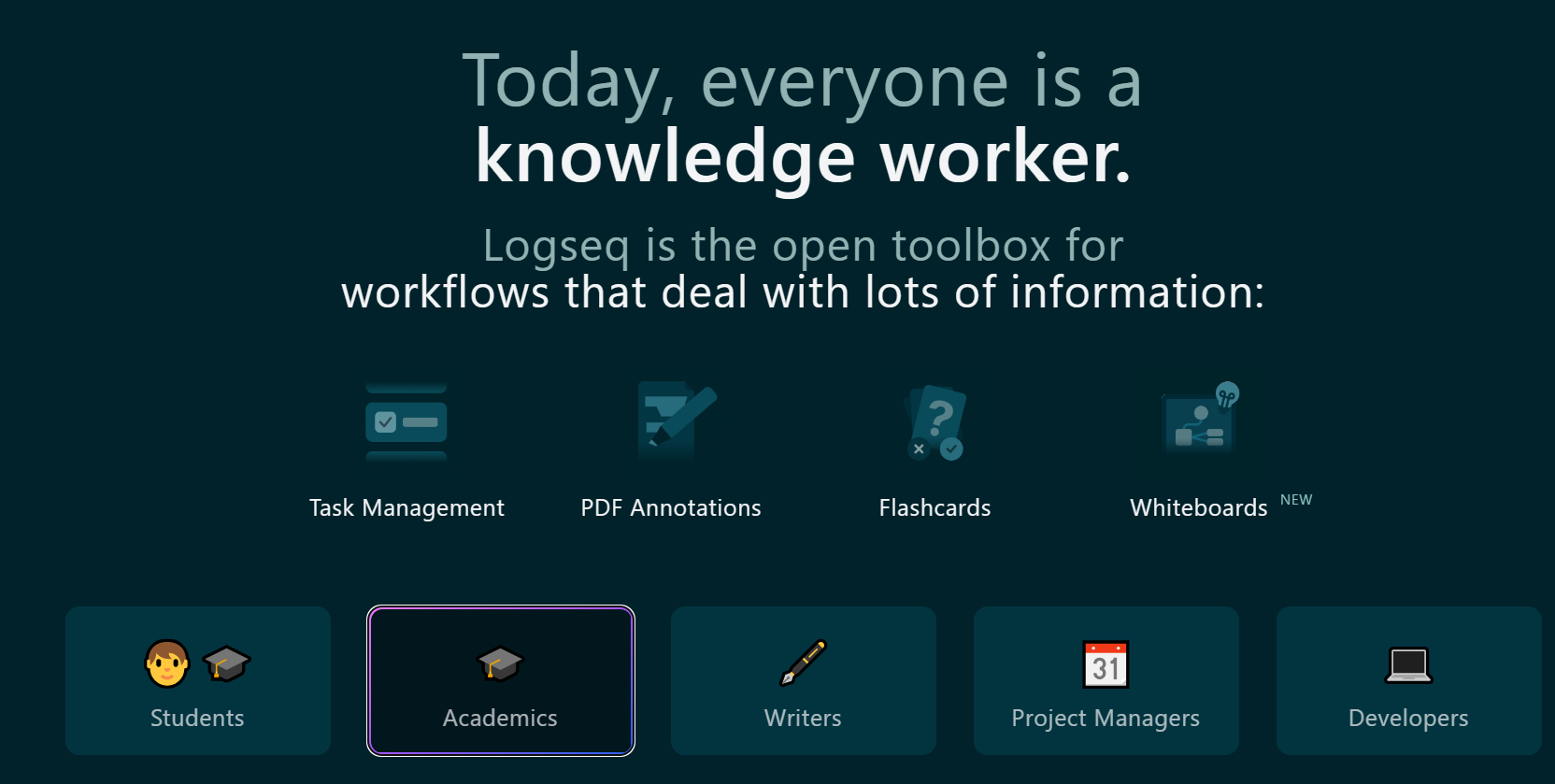
Logseq
Connect your notes, increase understanding.

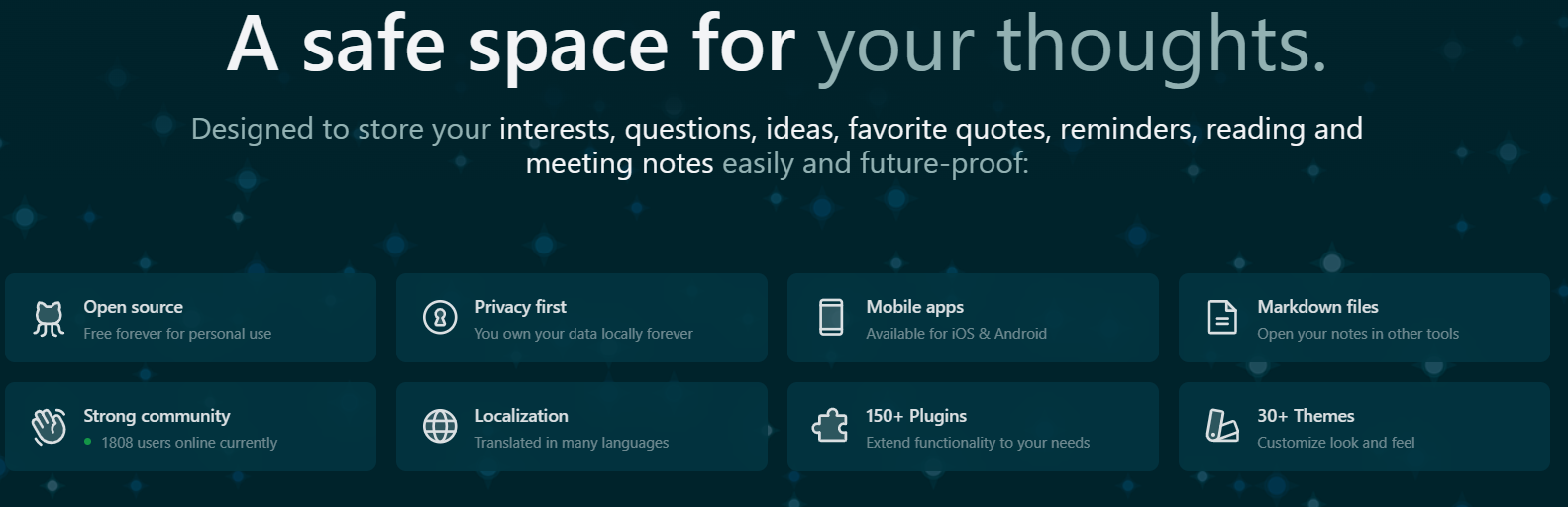
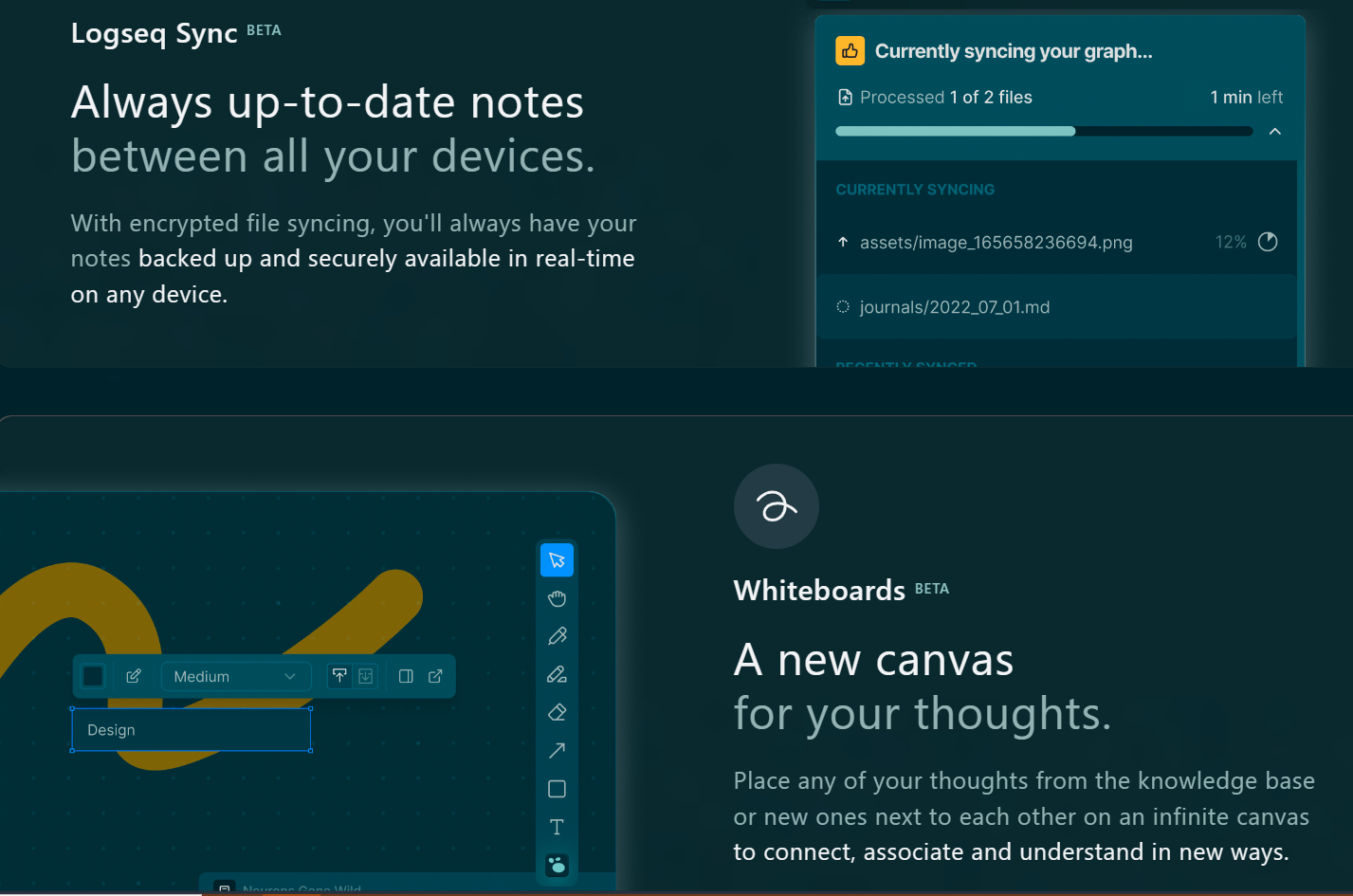
Has plugins (150+) for Hypothesis integration, time-synced notes on audio files, automatic captioning, PDF annotation, embedded drawings, chemistry diagrams, integrated terminals, graphical chart editing, flashcards and spaced repetition, and more.
Anyone can develop their own plugins with the plugin API.
Has apps for every major platform.
OneNote
Perhaps more intuitive to use than Obsidian, and is part of the Microsoft ecosystem. However, there are fewer plugins (for integration with other services) and the notes cannot be edited with other programs.
Offers better real-time collaboration features than the other offline-oriented options.
Has apps for every major platform and a web interface.
Primarily/Exclusively Online
These offer effortless real-time collaboration (whereas collaboration with the above [except OneNote] would be more like pushing to a Git repository) but are generally pricier, lack robust offline access to notes, and have much higher lock-in (meaning it’s difficult, if not nearly impossible, to migrate to other note systems). Editing using other editors is generally not possible, although usually there are export options. (However, lots of exporting and importing is not convenient and also does not make use of the collaborative features.)
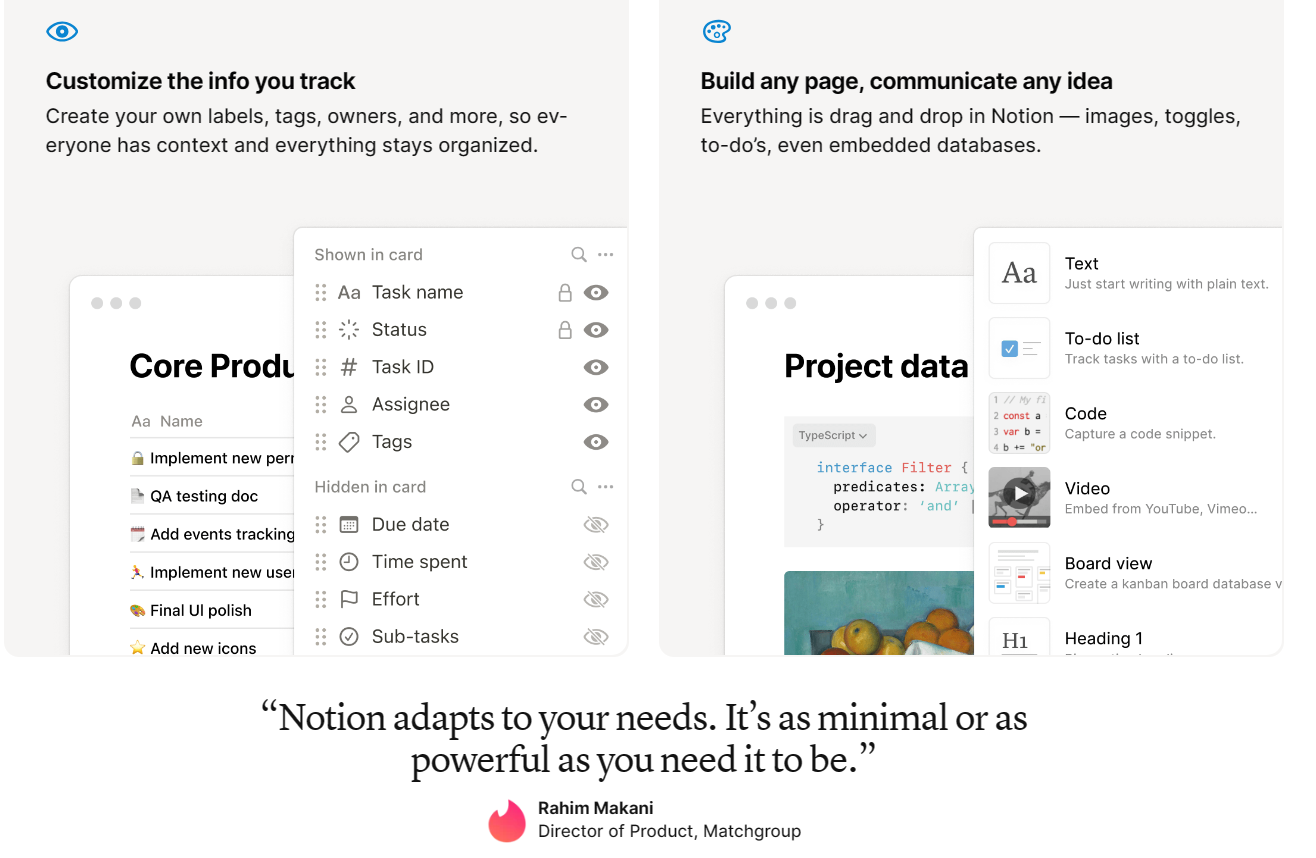
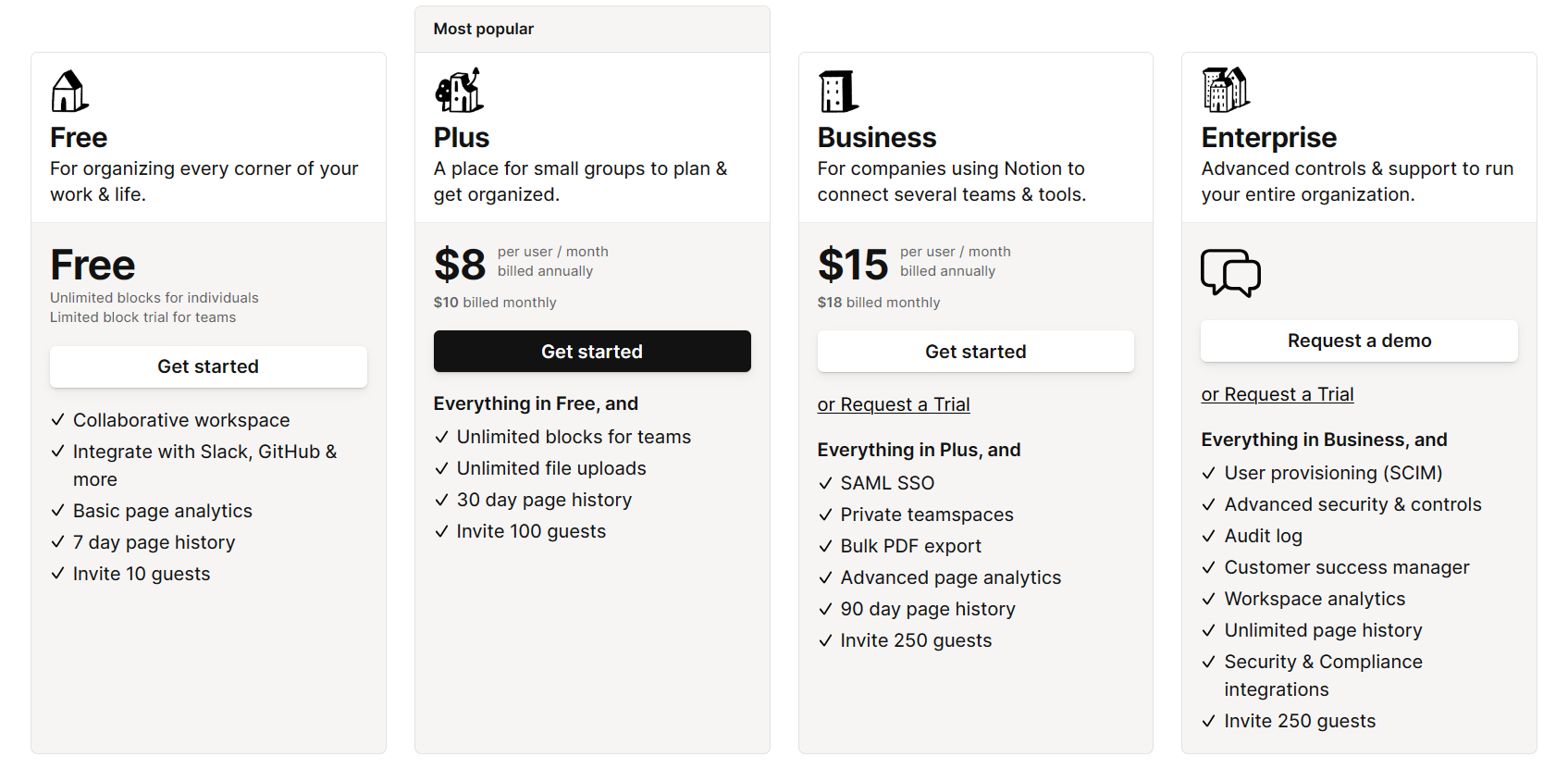
Notion
Has apps for every major platform and a web app.
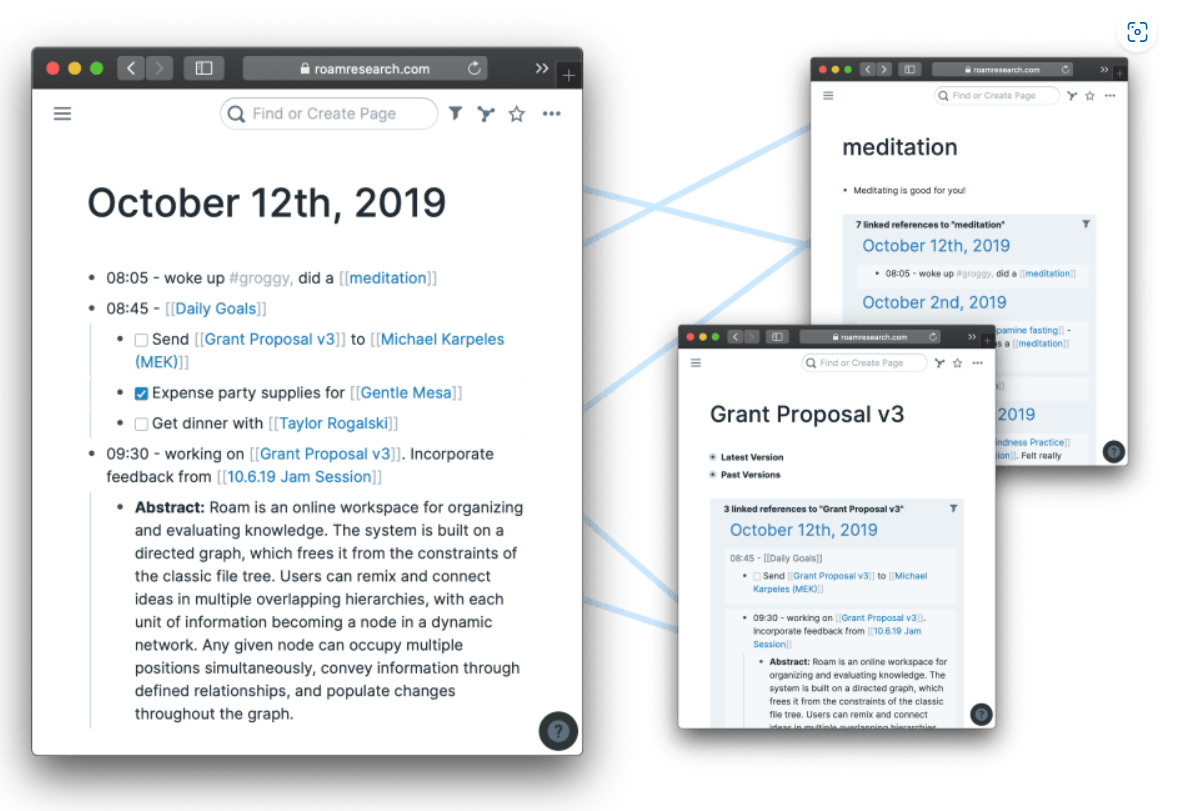
Roam Research
As easy to use as a document. As powerful as a graph database.
Roam helps you organize your research for the long haul.
Also has apps for every major platform, as well as a web interface.
Saga.so
Desktop apps for Windows and Mac (no Linux, mobile, or web interface at the moment).
Markdown editors geared towards research/academia
These are compatible with systems that are based on Markdown (.md) files, such as Obsidian and Logseq. (Note that while the online-oriented systems typically also make use of Markdown syntax, transparent access to Markdown files is not available.)
Zettlr

From idea to publication in one app: Zettlr accompanies you while writing your blog post, newspaper article, term paper, thesis, or entire book.
Privacy First:
Zettlr is Privacy First: There is no forced cloud-synchronization and all files stay on your computer.
From Idea to Publication:
Manage all your writing projects from one app: From the initial idea to a final publication, already typeset in the appropriate template.
First-class Citation Support:
Hook Zettlr into your reference manager to have all your sources when you need them.

Academic literature and citation management
Reference Managers
Zotero
I’ve noticed that more note-keeping, citation management, and bibliography tools have integration options for Zotero than do for Mendeley. This leads me to believe that Zotero is more popular / widely used. This could also be due to observation bias since I am personally only familiar with Zotero.
Has apps for all major platforms. Not the prettiest per se, but has plenty of useful features.
Note also zoterobib, an officially-endorsed bibliography tool. (Not the same as Zotero, but made by the same development team.)

Mendeley
Appears to be a subset of Elsevier, as its homepage (<www.mendeley.com>) redirected me to the Elsevier website after a short delay.
Article Managers
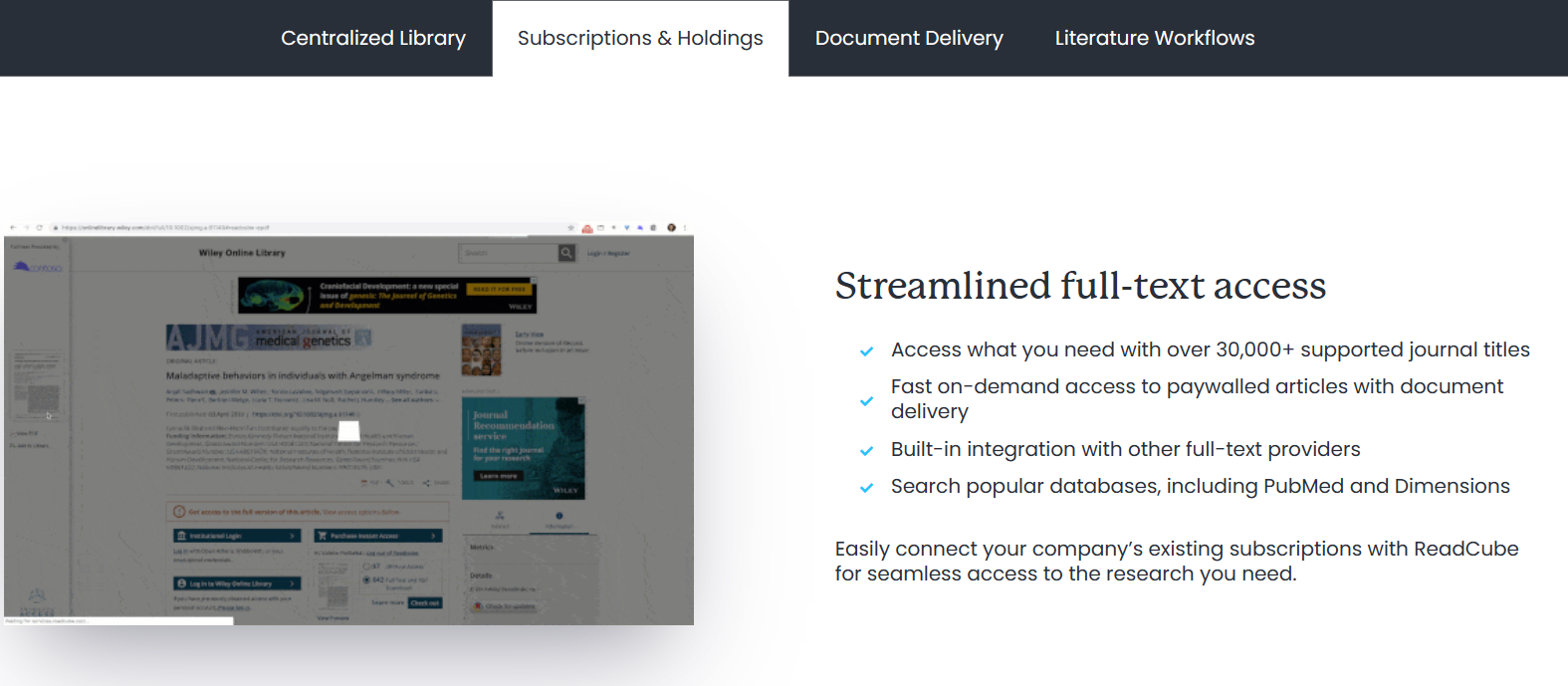
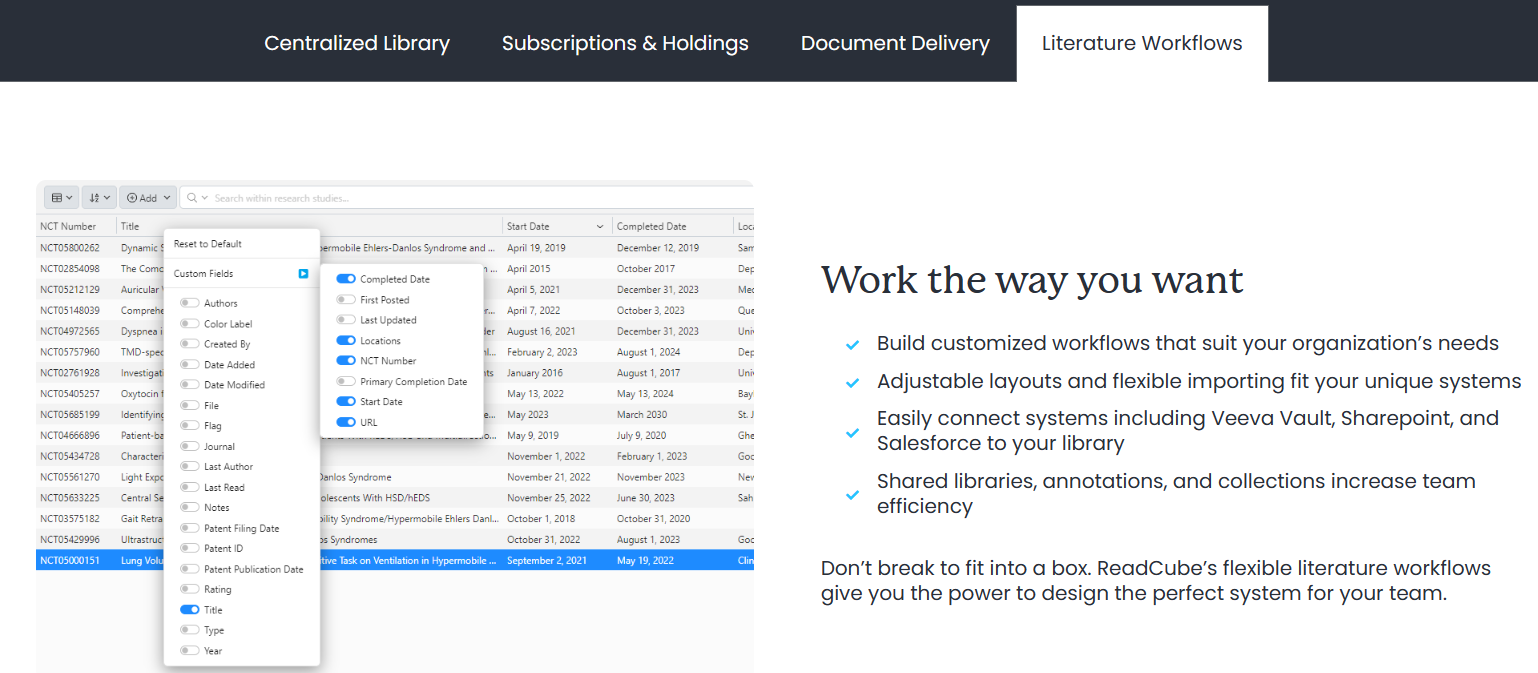
ReadCube

ReadCube’s literature management system helps businesses discover, organize, read, annotate, share, and cite research. Simplify your day-to-day so you’re free to make tomorrow’s discoveries.
The ReadCube website has a page where it provides comparisons of its services with those of Rightfind, Article Galaxy, Endnote, and Mendeley. I find it a bit suspicious that it doesn’t compare itself with Paperpile or any of the other popular similar services.
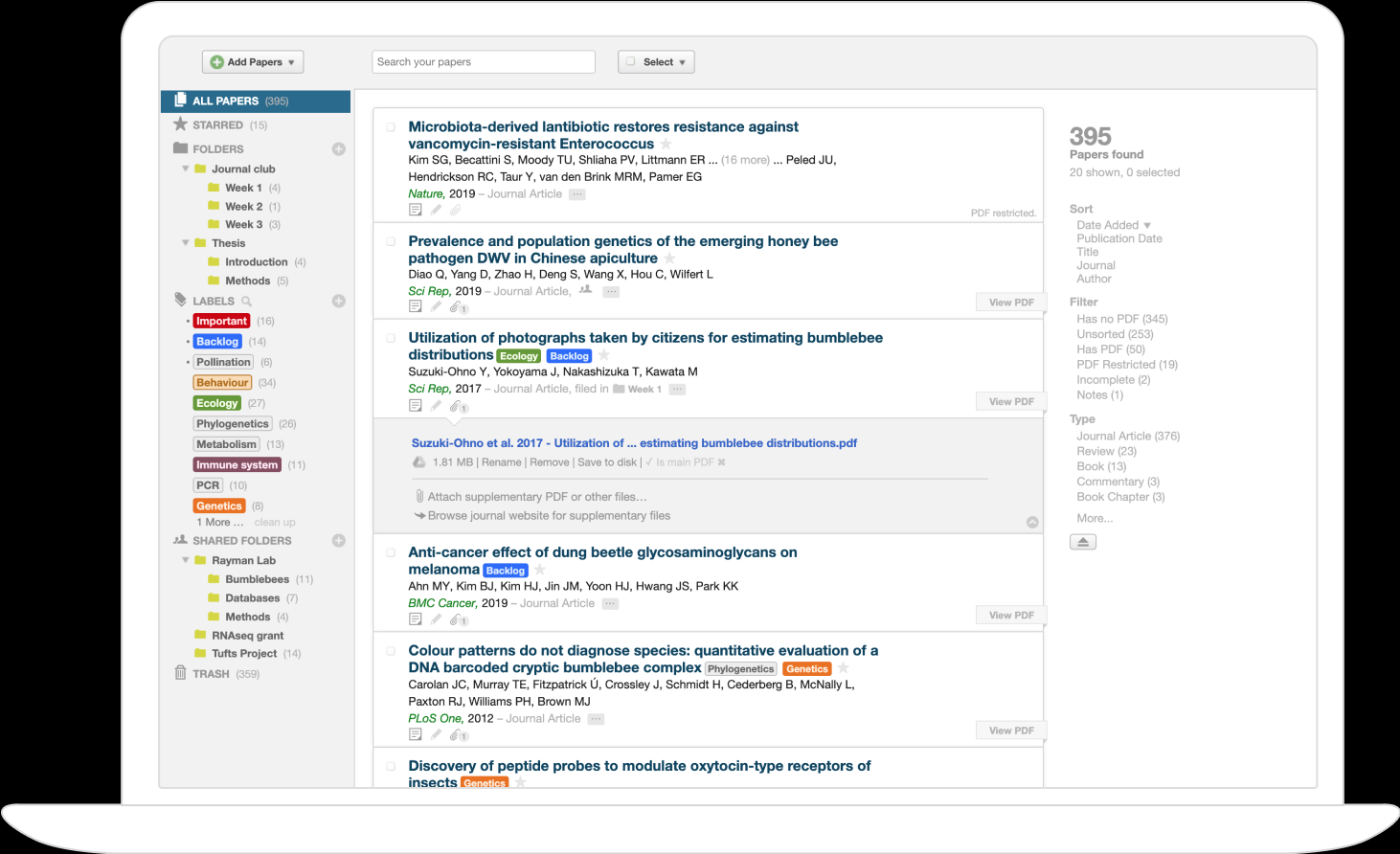
PaperPile

Manage your research library right in your browser.
See its Features page for an overview. (Categories: Manage References, Find and Collect, Organize PDFs, Highlight and annotate, Share and Collaborate, Cite in Google Docs).
Its Feature Roadmap is also available for viewing.
Advertises that it has a plugin for Microsoft Word and Google Docs. It also has mobile apps for Android/iOS.
Other
PaperMemory
It is a browser extension.
Parse papers you open automatically.
Papers are stored in your Memory automatically, without a click. You can then search them, tag them, take personal notes etc.
Match preprints to publications
By querying SemanticScholar, DBLP and CrossRef, PaperMemory can discover the proper publication of Arxiv pre-prints.
You live in your browser? So do your papers
Share papers to your favorite apps by copying:
- a BibTex entry for Overleaf
- a Markdown link [title](url) link for Github, HackMD or Notion
- a HyperText link for emails, Google Docs, Slack, etc.
Discover code repositories Using the PapersWithCode API, PaperMemory will match code repositories with papers in your Memory.
Enhance ArXiv.org
Display the actual pubication venue of published papers, a link to the code repository, copy the BibTex entry etc.
Instantly copy
.bib-compatible bibliography entries Export a paper’s BibTex entry directly from the extension, or bulk export BibTex entries by paper tag. You can even use PaperMemory to update the ArXiv entries of a stand-alone.bibfile.Highly customizable
Change the theme to light or dark, control the default link copied to your clipboard, add links to SciRate / HuggingFace Papers / Ar5iv / ArxivSanity, trigger parsing manually, export / import papers etc.
And many more features! Github Gist synchronization, regex-based automatic paper tagging, arbitrary website parsing to record Blog posts or dataset websites, etc.